Les Fichiers redoDate de publication : le 20 Octobre 2005 I. Les Fichiers Redo I.1. Introduction I.1.1. Contenu du Redo Log I.1.2. Comment Oracle écrit dans les fichiers de journalisation I.2. Informations sur les fichiers de journalisation I.3. Création des groupes et des membres de journalisation I.3.1. Création des groupes de journalisation I.3.2. Création des membres de journalisation I.4. Remplacement et renommination des membres de journalisation I.5. Suppression du groupe de journalisation I.6. Suppression des membres de journalisation I.7. Forcer les Log Switchs I.8. Vérification des blocs dans les fichiers de journalisation I.9. Initialisation des fichiers de journalisation II. Les Fichiers Redo Archivés II.1. Introduction II.2. Le mode NOARCHIVELOG et ARCHIVELOG II.2.1. Le mode NOARCHIVELOG II.2.2. Le mode ACHIVELOG II.3. Changement du mode d'archivage II.4. L'archivage manuel et l'archivage automatique II.5. Déstination des Archives II.5.1. Methode 1 : Utilisation du paramètre LOG_ARCHIVE_DEST_n II.5.2. Methode 2 : LOG_ARCHIVE_DEST et LOG_ARCHIVE_DUPLEX_DEST II.6. Statu des destinations d'archives II.7. Mode de transmission d'un journal II.7.1. Mode de transmission normal II.7.2. Mode transmission standby II.8. Gestion des pannes des destinations archives II.9. Trace du processus d'archivage II.10. Informations sur les vues des fichiers redo archivés II.10.1. Les vues dynamique II.10.2. La commande ARCHIVE LOG LIST III. Le Redo Log Buffer IV. Checkpoint IV-A. Les paramètres de checkpoint IV-A-1. Avant la 10g IV-A-2. Le paramètre FAST_START_MTTR_TARGET V-B. En cours V. Reglages des fichiers redo et du redo log buffer V-A. log file switch completion V-B. log file switch (checkpoint incomplete) V-C. L'attente de l'évènement log file sync V-A-1. fréquence très élevée des validations V-A-2. E/S lent V-A-3. Log Buffer trop grand V-D. log file parallel write VI. Le LOGMINNER VI-A. Introduction VI-B. Configuration du Logminer VI-C. Utilisation du Logminer VI-D. La vue V$LOGMNR_CONTENTS VI-E. DBMS_LOGMNR.START_LOGMNR VIII. Dump des fichiers Redo A. Dump basé sur le DBA (Data Block Address) B. Dump basé sur le RBA (Redo Block Address) C. Dump basé sur le temps D. Dump basé sur la couche et l'opcode. E. Dump des informations de l'entête du fichier F. Dump du fichier redo en entier IX. Les fichiers redo et les sauvegardes X. Appendice IX.1. RBA IX.2. RDBA et DBA I. Les Fichiers RedoI.1. Introduction
Oracle utilise les journaux redo pour être sûre que toute modification effectuée par
un utilisateur ne sera pas perdue s'il y'a défaillance du système. Les journaux
redo sont essentiels pour les processus de restauration. Quand une instance s'arrête
anormalement, il se peut que certains informations dans les journaux redos ne soient pas
encore écrites dans les fichiers de données. Oracle dispose les journaux redo en groupes.
Chaque groupe à au moins un journal redo. Vous devez avoir au minimum deux groupes distincts
de journaux redo (aussi appelé redo threads), chacun contient au minimum un seul membre.
Chaque base de données à ses groupes de journaux redo. Ces groupes, multiplexés ou non,
sont appelés instance du thread de redo. Dans des configurations typiques, une seule instance
de la base accède à la base Oracle, ainsi, seulement un thread est présent.
Dans un environnement RAC, deux ou plusieurs instances accèdent simultanément une seule
base de données et chaque instance à son propre thread de redo
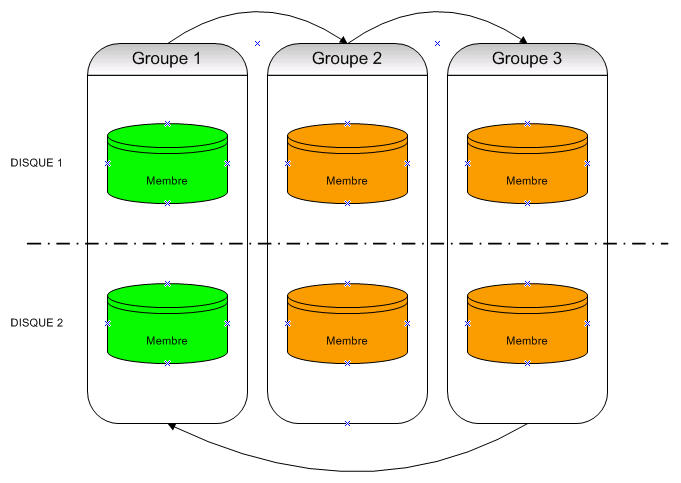 Groupe de fichiers de journalisations et les membres I.1.1. Contenu du Redo Log
Les fichiers de journalisation sont remplis par des enregistrements redo. Un enregistrement redo,
aussi appelé une entrée redo, est composé d'un groupe de vecteurs de change, qui est une
description d'un changement effectué à un bloc de la base. Par exemple, si on modifie
la valeur d'un salaire dans la table employee, on génère un enregistrement redo qui contient
des vecteurs de change décrivant les modifications sur le bloc du segment de données de la table,
le bloc de données du segment undo et la table de transaction des segments undo.
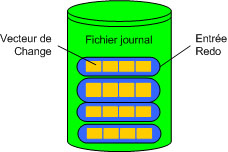 Les entrées redo enregistre les données qu'on peut utiliser pour reconstruire touts les changements effectués sur la base, inclus les segments undo. De plus, le journal redo protége aussi les données rollback. Quand on restaure la base en utilisant les données redo, la base lit les vecteurs de change dans les enregistrements redo et applique le changement aux blocs appropriés.
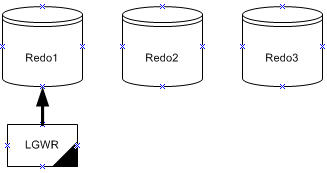
Les enregistrements redo sont mis d'une façon circulaire dans le buffer redo log de la mémoire SGA.
Et ils sont écrits dans un seul fichier de journalisation par le processus LGWR. Dés qu'une
transaction est comité, LGWR écrit les enregistrements redo de la transaction depuis
le buffer redo log du SGA vers le fichier journal redo, et attribut un SCN pour identifier
les enregistrements redo pour chaque transaction comité. Seulement quand tous les enregistrements
redo associés à la transaction donnée sont sans incident sur le disque dans les journaux en ligne
et que le processus utilisateur a notifié que la transaction à été comité.
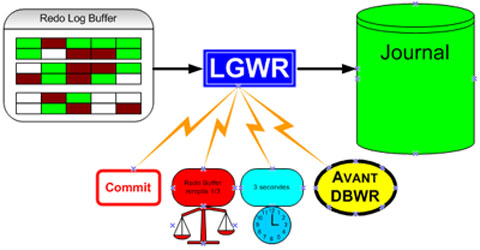 Les enregistrements redo peuvent aussi être écrits dans le fichier journal redo avant que la transaction correspondante soit comité. Si le buffer redo log est plein ou une autre transaction à comité, LGWR vide toutes les entrées des journaux redo du buffer redo log dans le fichier journal redo, bien que certain enregistrements redo ne devrait pas être validés. Si nécessaire, oracle peut annuler ces changements. I.1.2. Comment Oracle écrit dans les fichiers de journalisation
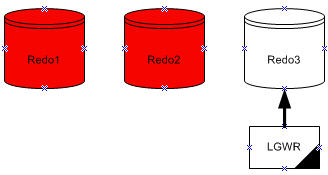
La base oracle exige au minimum deux fichiers de journalisation.
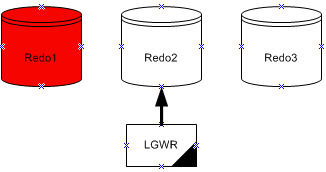
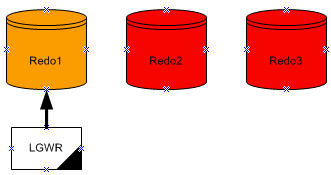
LGWR écrit dans les fichiers de journalisation d'une façon circulaire. Quand le fichier journal
redo courant est plein, LGWR commence à écrire dans le prochain fichier journal redo disponible.
Quand le dernier est plein, LGWR commence à écrire dans le premier journal redo.
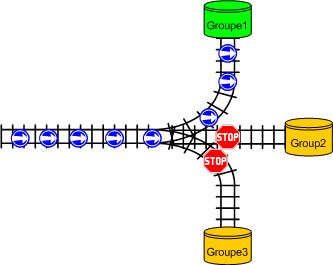
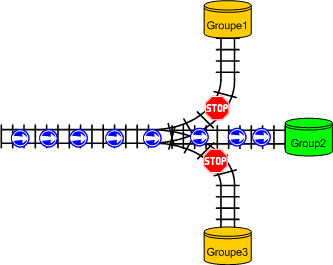
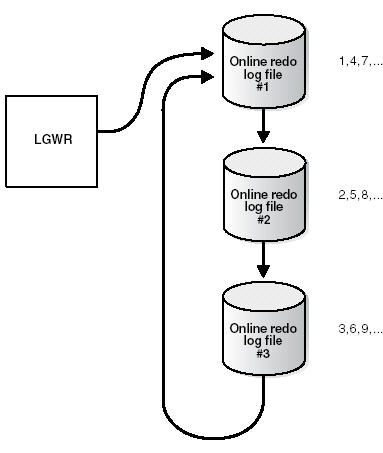 Figure 1
Les fichiers journaux Active (Current) et Inactive
Oracle utilise un seul fichier de journalisation à la fois pour stocker les enregistrements redo depuis le redo log buffer. Le fichier de journalisation dont le processus LGWR est entrains d'écrire dedans est appelé le fichier de journalisation courant.
Les fichiers de journalisation qui sont nécessaire à la restauration de la base sont appelés les fichiers de journalisation actives. Les fichiers de journalisation qui ne sont pas nécessaire à la restauration s'appelles les fichiers de journalisation inactives.
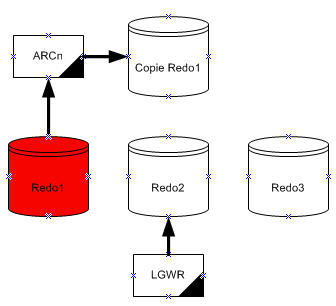
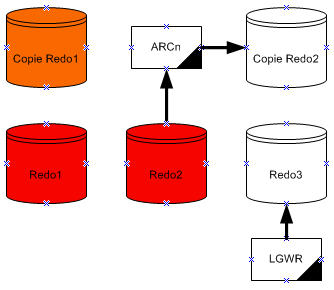
Si on a activé l'archivage (mode ARCHIVELOG), alors la base ne peut pas réutiliser ou sur écrire dans le fichier de journalisation en ligne tant que l'un des processus ARCn n'a pas archivé ses contenus. Si l'archivage est désactivé (mode NOARCHIVELOG), alors quand le dernier fichier de journalisation est plein, LGWR continue en sur écrivant le premier fichier active disponible.
Les Log Switches et les numéros de séquence du journal
Un log switch est le point où la base arrête d'écrire dans l'un des fichiers de journalisation en ligne et commence à écrire dans un autre. Normalement, un log switch survient quand le fichier de journalisation courant est complètement rempli et il doit continuer à écrire dans le fichier de journalisation suivant. Pourtant, on peut configurer les log switche de se reproduire dans des intervalles réguliers, sans soucier si le fichier de journalisation en cours est complètement rempli. On peut aussi forcer les log switch manuellement.
Oracle assigne à chaque fichier de journalisation un nouveau numéro de séquence chaque fois un log switch arrive et le processus LGWR commence à écrire dedans. Quand oracle archive les fichiers de journalisation, le log archivé garde le numéro de séquence du journal. Le fichier de journalisation qui est recyclé fournis le prochain numéro de séquence du journal disponible.
Chaque fichier de journalisation en ligne ou archivé est identifié uniquement par son numéro de séquence (log sequence).
Durant un crash, l'instance ou une restauration media , la base applique proprement les fichiers de journalisation dans un ordre croissant en utilisant le numéro de séquence du fichier de journalisation archivé nécessaire et des fichiers de journalisation.
I.2. Informations sur les fichiers de journalisation
Les vues V$THREAD, V$LOG, V$LOGFILE et V$LOG_HISTORY fournis des informations
sur les journaux Redo.
La vue V$THREAD donne les informations sur le fichier de journalisation en cours.
La vue V$LOG donne les informations en lisant dans le fichier de contrôle
au lieu dans le dictionnaire de données.
Pour voir les noms des membres d'un groupe on utilise la vue V$LOGFILE
GROUP# est le numéro du groupe Redo Log.
STATUS prends la valeur INVALID si le fichier est inaccessible,
STALE si le fichier est incomplet , DELETED si le fichier n'est plus utilisé
et la valeur blanc si le fichier est en cours d'utilisation.
MEMBER est le nom du membre Redo Log
A partir de la 10g on'a une nouvelle colonne dans la vue V$LOGFILE : IS_RECOVERY_DEST_FILE.
Cette colonne se trouve dans les vues V$CONROLFILE, V$ARCHIVED_LOG, V$DATAFILE_COPY,
V$DATAFILE et V$BACKUP_PIECE, elle prends la valeur YES si le fichier à été crée
dans la région de restauration flash.
La vue V$LOG_HISTORY contient des informations concernant l'historique des
fichiers journaux à partir du fichier de contrôle. Le maximun que peut retenir
la vue depends du paramètre MAXLOGHISTORY.
La seule solution pour initialiser cette vue, il faut recréer le fichier de contrôle.
voir mon tuto : fichier de contôle ou utiliser CONTROL_FILE_RECORD_KEEP_TIME.
Dans cette exemple on a l'erreur oracle suivante :
On voit que le problème vient de la section 9 ce qui veut dire LOG HISTORY
Ce qui montre que RECORD_USED à atteint le maximum autorisé RECORD_TOTAL.
La solution est de mettre le paramètre CONTROL_FILE_RECORD_KEEP_TIME à 0 dans le
fichier d'initialisation ou utiliser la commande suivante :
MAXLOGHISTORY augmente dynamiquement quand CONTROL_FILE_RECORD_KEEP_TIME
Est different de 0 mais il ne depasse jamais la valeur 65535.
Supposons que control_file_record_keep_time = 30 (30 jours) et qu'à
chaque 30 secondes un archive log est géneré.
Pour 30 jours, on'aura 86400 journaux ce qui dépassera la valeur 65535. Pour corriger le problème
on met la paramètre control_file_record_keep_time à 0 et pour l'éviter on augmente la taille
des fichiers redo.
I.3. Création des groupes et des membres de journalisation
Pour créer un nouveau groupe de fichier de journalisation ou un membre, on doit avoir le privilège système
ALTER DATABASE. La base peut avoir au maximum MAXLOGFILES groupes.
I.3.1. Création des groupes de journalisation
Pour créer un nouveau groupe de fichiers journalisation, on utilise
la requête ALTER DATABASE avec la clause ADD LOGFILE.
Par exemple ::
On peut spécifier le numéro qui identifie le groupe en
utilisant la clause GROUP :
L'utilisation des numéros de groupes facilite l'administration des groupes de journalisation.
Le numéro de groupe doit être entre 1 et MAXLOGFILES. Surtout ne sauter pas
les numéros de groupes (par exemple 10, 20,30), sinon on consomme inutilement
de l'espace dans les fichiers de contrôles.
I.3.2. Création des membres de journalisation
Dans certain cas, il n'est pas nécessaire de créer complètement un groupe de fichiers
de journalisation. Le groupe peut déjà exister car un ou plusieurs membre a été supprimé
(par exemple, suite une panne d'un disque). Dans ce cas, on peut ajouter
de nouveaux membres dans le groupe existant.
Pour créer un nouveau membre de fichier de journalisation d'un groupe existant, on utilise la commande ALTER DATABASE avec la clause ADD LOGFILE MEMBER. Dans l'exemple suivant on ajoute un nouveau membre au groupe de journalisation numéro 2 :
Noter que le nom du fichier doit être indiqué, mais sa taille n'est pas obligatoire.
La taille du nouveau membre est déterminé à partir de la taille des membres existants du groupe.
Quand on utilse ALTER DATABASE, on peut identifier alternativement le groupe cible
en spécifiant tous les autres membres du groupe dans la clause TO, comme le montre
l'exemple suivant :
I.4. Remplacement et renommination des membres de journalisation
On peut utiliser les commandes OS pour déplacer les fichiers de journalisation, après on utilise
la commande ALTER DATABSE pour donner leurs nouveaux noms (emplacement) connu par la base.
Cette procèdure est necessaire, par exemple, si le disque actuellement utilisé pour certains
fichiers redo logs doit être retiré, ou si les fichiers de données et certains fichiers
de journalisation se trouvent dans un même disque et devrait être séparés pour réduir la contention.
Pour renommer un membre de fichiers de journalisation, on doit avoir le privillège système ALTER DATABASE.
En plus, On doit aussi avoir les privilèges système pour copier les fichiers dans le repertoire
désiré et les privilèges pour ouvrir et sauvegarder la base de données.
Avant de déplacer les fichiers de journalisations, ou tous autres changements de structures de la base, sauvegarder
complètement la base. Par precaution, après la renommination ou le déplacement d'un ensemble de
fichiers fichiers de journalisation, effectuer immediatement une sauvegarde du fichier de contrôle.
Pour déplacer les fichiers de journalisations, on utilise les étapes suivantes :
Les étapes à suivre pour renommer les membres des journaux
1. Arrêter la base.
2. Copier les fichiers de journalisation dans le nouveau emplacement.
L'exemple suivant utilise les commandes OS (UNIX) pour déplacer les membres
des journaux dans un nouveau emplacement :
3. Démarrer la base avec un mount, sans l'ouvrir.
4. Renommer le membre de fichier de journalisation.
Use the ALTER DATABASE statement with the RENAME FILE clause to rename the
database redo log files.
5. Ouvrir la base normalement.
La modification du fichier journal prends effet à l'ouverture de la base.
I.5. Suppression du groupe de journalisation
Dans certains cas, on doit supprimer un groupe en entier. Par exemple,
on veut réduir le nombre de groupes. Dans d'autres cas, on doit supprimer un ou plusieurs
membres. Par exemple, si certains memebres se trouvent dans un disque défaillant.
 Suppression d'un groupe Pour supprimer un groupe de journaux, on doit avoir le privilège système ALTER DATABASE.
Avant de supprimer un groupe de journaux, il faut prendre en considération les restrictions
et les precautions suivantes :
Pour voir ce qui se passe, utilisez la vue V$LOG.
Supprimer un groupe de journaux avec la commande ALTER DATABASE en utilisant la clause DROP LOGFILE.
Dans cette exemple on supprime le groupe de journaux ayant comme numéro 3 :
Quand un groupe de journaux est supprimé de la base, et on n'utilise pas l'OMF, les fichiers
OS ne seront pas supprimés du disque. Il faut utiliser les commandes OS pour les supprimés
physiquement.
Quand on utilise OMF, le nettoyage des fichiers OS se fait automatiquement.
I.6. Suppression des membres de journalisation
Pour supprimer un membre d'un fichier de journalisation, on doit avoir le privilège système ALTER DATABASE.
Pour supprimer un membre inactive d'un fichier de journalisation, on utilise la commande ALTER DATABASE avec la clause DROP LOGFILE MEMBER.
 Suppression d'un membre La commande suivante supprime le journal /oracle/dbs/log3c.rdo :
Quand un membre d'un journal est supprimé, le fichier OS n'est pas supprimé du disque.
Pour supprime un membre d'un groupe actif, on doit forcer en premier le log switch.
I.7. Forcer les Log Switchs
Le log switch se produit quand LGWR s'arrête d'écrire dans un groupe de journaux et commence à écrire
dans un autre. Par defaut, un log switch se produit automatiquement quand le groupe du fichier
de journalisation en cours est remplis.
On peut forcer un log switch pour que le groupe courant soit inactif et disponible pour
des opérations de maintenances sur les fichiers journaux. Par exemple, on veut supprimer le groupe
actuellement actif, mais on est incapable de le supprimer tant qu'il est actif. On doit aussi
obliger un switch log si le groupe actuellement actif à besoin d'être archivé dans un temps
spécifique avant que les membres du groupe seront complètement remplis.
Cette option est utile dans des configurations où les fichiers de journalisation sont assez larges et
ils prennent plus de temps pour se remplir.
Pour forcer un log switch, on doit avoir le privilège ALTER SYSTEM. Utilisez la commande
ALTER SYSTEM avec la clause SWITCH LOGFILE.
La commande suivante force un log switch:
I.8. Vérification des blocs dans les fichiers de journalisation
On peut configurer la base pour utiliser le CHECKSUMS, afin que les blocs des
fichiers journaux soit vérifiés. Si on affecte le paramètre d'initialisation
DB_BLOCK_CHECKSUM à TRUE, Oracle calcule le checksum pour chaque bloc oracle
quand il écrit dans le disque, y compris les blocs des journaux. Le checksum
est stocké dans l'entête du bloc.
Oracle utilise le checksum pour detecter les blocs corrompu dans les fichiers de journalisation.
La base vérifie le bloc du journal quand le bloc est lit à partir du journal archivé durant la
restauration et quand il écrit le bloc dans le journal archivé. Une erreur sera detecté et écrite
dans le fichier d'alert, si une corruption est detectée.
Si une corruption est detecté dans un bloc du journal pendant son archivage, le système
tente de lire le bloc depuis un autre membre dans le groupe. Si le bloc est corrompu
dans tous les membres du groupe des journaux, alors l'archivage ne peut pas se poursuivre.
La valeur par défaut du paramètre DB_BLOCK_CHECKSUM est TRUE. La valeur de ce paramètre
peut être modifié dynamiquement en utilisant ALTER SYSTEM
I.9. Initialisation des fichiers de journalisation
On peut initialiser un fichier de journalisation sans arrêter la base, par exemple,
si le fichier de journalisation est corrompu.  Initialisation d'un groupe
On peut utiliser cette commande si on ne peut pas supprimer les journaux , il y'a deux situations :
Si le fichier journal corrompu n'est pas encore archivé, on utilise la clé UNARCHIVED.
Cette commande initialise les fichiers journaux corrompus et évite leur archivage.
Si on initialise le fichier journal qui est nécessaire pour la restauration ou la sauvegarde,
on ne peut plus restaurer depuis cette sauvegarde.
Pour initialiser un journal non archivé qui est nécessaire pour mettre un tablespace
hors ligne en ligne, on utilise la clause UNRECOVERABLE DATAFILE dans la commande
DATABASE CLEAR LOGFILE.
Si on initialise un journal nécessaire pour mettre un tablespace hors ligne
en ligne, on sera incapable de mettre le tablespace en ligne une autre fois.
On est obligé de supprimer le tablespace ou effectuer une restauration incomplète.
Il faut noter que le tablespace mis hors ligne normalement n'a pas besoin de restauration.
II. Les Fichiers Redo ArchivésII.1. Introduction
En cours
II.2. Le mode NOARCHIVELOG et ARCHIVELOGII.2.1. Le mode NOARCHIVELOG
Quand la base est en mode NOARCHIVELOG, l'archivage des journaux est désactivé. Le fichier de contrôle indique que les groupes remplis ne sont plus nécessaires et dès qu'ils sont inactifs après un log switch, le groupe sera disponible pour une réutilisation par LGWR.
Le mode NOARCHIVELOG protège la base contre une défaillance de l'instance, mais non pas contre une défaillance media. Seulement les modifications récentes dans la base, stockés dans les groupes de fichiers redo en ligne qui seront disponible pour la restauration de l'instance.
En mode NOARCHIVELOG on ne peut pas exécuter une sauvegarde en ligne d'une tablespace. Pour restaurer la base en mode NOARCHIVELOG, on peut seulement utiliser une sauvegarde complète quand la base était fermée. Dans ce mode, il faut faire des sauvegardes régulièrement.
II.2.2. Le mode ACHIVELOG
Quand la base est en mode ARCHIVELOG, on active l'archivage des fichiers de journalisation. Le fichier de contrôle de la base signale que les groupe contenant des fichiers de journalisation plein, ne peut pas être utiliser par LGWR tant que le groupe n'a pas été archivé.
II.3. Changement du mode d'archivage
Pour modifier le mode d'archivage de la base, on utilise la commande ALTER DATABASE avec la clause ARCHIVELOG ou NOARCHIVELOG et il faut être connecté avec des privilèges d'administrateur (AS SYSDBA).
Dans cette exemple on montre comment activer le mode ARCHIVELOG :
1. Arrêter la base.
On ne peut pas modifier le mode ARCHIVELOG en NOARCHIVELOG si la base à besoin d'une restauration media.
2. Sauvegarder la base.
Avant de faire des modifications majeur dans la base, toujours sauvegarder votre base pour se protegé d'un autre nouveau problème.
3. Editer le fichier d'initialisation pour ajouter les paramètres qui spécifies la déstination des archives. (Voir Destination des archives).
4. Démarrer la base en mode mount sans l'ouvrir.
5. Modifier le mode d'archivage et ouvrir la base.
6. Arrêter la base..
7. Sauvegarde la base.
La fait de modifier le mode d'archivage mettra à jours le fichier de contrôle ce qui rendra les anciens sauvegardes inutilisables.
II.4. L'archivage manuel et l'archivage automatique
Dans Oracle 10g, l'archivage automatique est activé par la commande SQL suivante :
Si la base est en mode ARCHIVELOG, Oracle archive les fichiers journaux dès qu'ils sont remplis. Le journal en entier doit être archivé avant d'être utilisé.
Avant 10g, les fichiers journaux sont marqués comme prêt pour être archivé ce qui ne signifie pas qu'ils devraient être archivés automatiquement. Il fallait renseigné le parametre d'intialisation :
Mettre ce paramètre à TRUE démarera un process qui consiste à copier un fichier de journalisation dans le repertoire des journaux archivés. La destination et le format du nom des fichiers de journalisation archivés sont specifiés par deux paramètres, , LOG_ARCHIVE_DEST et LOG_ARCHIVE_FORMAT.
Specifie le nom du repertoire où Oracle doit écrire les fichiers archivés
Et
Specifie le format du nom des fichiers archivés. Dans ce cas, le fichier doit commencer par ORCL puis le numéro de sequence du journal et finira par .ARC.
Les autres options sont :
%s : le numéro de sequence du journal sans zero-padding à gauche
%T : le numéro du redo thread avec zero-padding
%t : le numéro du redo thread sans zero-padding
Par exemple, pour si on veut que les noms des fichiers archivés contient les numéros du thread et de la sequenec avec zero-padding :
II.5. Déstination des Archives
On a le choix d'archiver les journaux dans une seule destination ou dans plusieurs. Si on choisit une seule destination, alors on utilise le paramètre LOG_ARCHIVE_DEST. Et si on choisit plusieurs destinations, on 'aura le choix entre 10 destinations (paramètre LOG_ARCHIVE_DEST_n) ou archiver seulement dans les destinations primaire et secondaire en utilisant LOG_ARCHIVE_DEST et LOG_ARCHIVE_DUPLEX_DEST.
Voici un tableau qui récapitule le choix du multiplexage :
II.5.1. Methode 1 : Utilisation du paramètre LOG_ARCHIVE_DEST_n
On utilise le paramètre LOG_ARCHIVE_DEST_n (avec n un entier antre 1 et 10) pour désigner l'un des dix destinations d'archives.
Si on utilise la clé LOCATION, il faut spécifier un répertoire valide de l'OS. Si on spécifie SERVICE, Oracle traduit le nom du service réseau à travers le fichier tnsnames.ora en descripteur de connexion. Le descripteur contient les informations nécessaires pour se connecter la base remote. Le nom du service doit être associé au SID de la base, de cette façon la base met à jours correctement la section log history du fichier de contrôle pour une base standby.
Pour fixer la destination des fichiers redo archivés en utilisant le paramètre d'initialisation LOG_ARCHIVE_DEST_n :
1. Arrêter la base.
2. On fixe le paramètre d'initialisation LOG_ARCHIVE_DEST_n. Par exemple
Si on archive dans une base standby, on utilisera le mot clé SERVICE. Par exemple :
3. En option, on fixe le paramètre d'initialisation LOG_ARCHIVE_FORMAT.
L'incarnation de la base change quand elle est ouverte avec l'option RESETLOGS. Le fait de spécifier %r, provoquera la capture de l'ID resetlogs dans le nom du fichier redo archivé, ce qui nous facilites d'effectuer une restauration depuis la sauvegarde de la dernière incarnation de la base.
II.5.2. Methode 2 : LOG_ARCHIVE_DEST et LOG_ARCHIVE_DUPLEX_DEST
Si on veut spécifier au maximum deux locations, alors c'est mieux d'utiliser le paramètre LOG_ARCHIVE_DEST pour spécifier la destination d'archive primaire et LOG_ARCHIVE_DUPLEX_DEST pour spécifier la destination d'archive secondaire. Toutes les locations doivent être en local.
Pour cela, Il faut :
1. Arrêter la base.
2. Spécifier les paramètres LOG_ARCHIVE_DEST et LOG_ARCHIVE_DUPLEX_DEST (on peut utiliser la commande ALTER SYSTEM pour les modifiés dynamiquement).
Par exemple
3. Fixer le paramète d'initialisation LOG_ARCHIVE_FORMAT
II.6. Statu des destinations d'archives
Toutes les destinations d'archives ont des caractéristiques variables pour déterminer leur statut :
Valid/Invalid : indique si la location du disque et l'information sur le nom du service est specifié et valide.
Enabled/Disabled : indique l'état de la disponibilité de la location et si la base peut utiliser cette déstination.
Active/Inactive : Indique s'il y'a un problème pour accéder à la destination.
Plusieurs combinaisons sont possibles. Pour obtenir la statu en cours et d'autres informations sur chacune des destinations, on utilise alors la vue V$ARCHIVE_DEST.
En 10.2 la vue V$ARCHIVE_DEST à d'autres nouveau champs : MAX_CONNECTIONS, VALID_NOW , VALID_TYPE, VALID_ROLE, DB_UNIQUE_NAME et VERIFY
Le paramètre d'initialisation LOG_ARCHIVE_DEST_STATE_n (n un entier entre 1 et 10) nous permet de contrôler l'état de la disponibilité d'une destination (n) spécifique.
ENABLED : indique que la base peut utiliser la destination.
DEFER : indique que cette location est temporairement désactivée.
ALTERNATE : indique que cette destination est alternée
II.7. Mode de transmission d'un journal
Les deux modes pour transmettre les archivelogs dans leurs déstinations sont : normal archiving transmission et standby transmission. La transmission normal concerne la transmission des fichiers dans des disques locaux. Standby transmission concerne la transmission des fichiers à travers le reseau soit en local ou remote dans une base standby
II.7.1. Mode de transmission normal
En mode de transmission normal, La destination de l'archive est un autre disque du serveur de la base. Dans cette configuration, l'archive n'est plus concurrent avec les autres fichiers réclamés par l'instance et peut finir rapidement. Il faut spécifier la destination soit avec LOG_ARCHIVE_DEST_n ou LOG_ARCHIVE_DEST.
Pour la bonne pratique, il faut toujours sauvegarder les fichiers redo archivés dans un support de stockage comme les bandes. Le rôle primordial des fichiers redo archivés est la restauration.
II.7.2. Mode transmission standby
En mode de transmission standby, la destination de l'archive est soit en local ou en base standby distante.
Si nous manipulons notre base standby en mode managed recovery, nous pourrons conserver notre base standby synchronisé avec notre base source en appliquant automatiquement les redo archivés transmis.
Pour transmettre les fichiers avec succès à la base standby, soit ARCn ou le processus serveur doit faire ce qui suit :
Chaque processus ARCn à son correspondant RFS pour chaque destination standby. Par exemple, si trois processus ARCn sont archivés dans deux bases standby, alors Oracle établi six connections RFS.
On transmis les journaux archivés à travers le réseau vers un emplacement distant en utilisant les Services Oracle Net. L'archive distant est indiqué en spécifiant au nom du service Oracle Net comme un attribut de la destination. La base Oracle traduit alors le nom du service, par le fichier tnsnames.ora, pour connecter le descripteur. Le descripteur contient l'information nécessaire pour se connecter à la base distante. Le nom du service doit avoir le SID de la base, de telle façon à ce que la base met à jours correctement la section log history dans le fichier de contrôle pour la base standby.
Le processus RFS, qui s'exécute dans le nud de destination, agi comme un serveur réseau au client ARCn. Essentiellement, ARCn envoi l'information au RFS, qui la transmis à la base standby.
Le processus RFS, qui est réclamé quand on archive dans une destination distante, est responsable des taches suivantes :
Les fichiers redo archivés sont essentiels pour maintenir une base standby, qui est une réplique exacte de la base. Nous pourrons fonctionner notre base mode archive standby, qui mis à jours automatiquement la base standby avec les fichiers redo archivés depuis la base d'origine.
II.8. Gestion des pannes des destinations archives
Le paramètre facultatif LOG_ARCHIVE_MIN_SCCEED_DEST détermine le nombre minimum de destinations à laquelle la base doit archivé les groupes redo avec succès avant qu'elle doive réutiliser les fichiers redo en ligne. La valeur par défaut est 1. Les valeurs valides pour n sont 1 et 2 si on utilise le duplexage ou 1 à 10 si on utilise le multiplexage.
Le paramètre LOG_ARCHIVE_DEST_n nous permet de spécifier si la destination est OPTIONAL
(par défaut) ou MANDATORY. Le paramètre LOG_ARCHIVE_MIN_SUCCEED_DEST utilise toutes
les destinations MANDATORY plus quelques destinations OPTIONAL non-standby pour déterminer
si LGWR peut mettre à jours le journal en ligne. Les règles suivantes s'appliquent :
Si une destination MANDATORY échoue, contenant une destination standby MANDATORY, Oracle ignorera le paramètre LOG_ARCHIVE_MIN_SUCCEED_DEST.
La valeur du paramètre LOG_ARCHIVE_MIN_SUCCEED_DEST ne peut pas être plus grand que le nombre de destinations, non plus que le nombre de destination MANDATORY plus le nombre de destinations local OPTIONAL.
Si on DEFER une destination MANDATORY, et la base met un journal redo en ligne sans transférer le log archivé dans le site standby, alors on doit transférer le log au standby manuellement.
Si on duplexe les fichiers redo archivés, on peut établir quelles destinations sont
obligatoires ou facultatives en utilisant les paramètres LOG_ARCHIVE_DEST et
LOG_ARCHIVE_DUPLEX_DEST. Les règles suivantes s'appliquent :
On peut voir la relation entre les paramètres LOG_ARCHIVE_DEST_n et LOG_ARCHIVE_MIN_SUCCEED_DEST plus facilement dans le scénario suivant :
Dans ce scénario, on archive trois destinations en local, et dans chacun d'eux on déclare OPTIONAL. Le tableau suivant illustre les valeurs possibles du LOG_ARCHIVE_MIN_SUCCEED_DEST.
Ce scénario nous montre quand même de ne pas fixer explicitement n'importe quelles destinations à MANDATORY en utilisant le paramètre LOG_ARCHIVE_DEST_n, la base doit archivé avec succès dans un ou plusieurs emplacements quand LOG_ARCHIVE_MIN_SUCCED_DEST est fixé à 1,2 ou 3.
Considérons les cas suivants :
Ce tableau montre les valeurs possibles pour LOG_ARCHIVE_MIN_SUCCEED_DEST=n. Ce cas montre que la base doit être archivée dans les destinations spécifiées par MANDATORY, sans soucier si on fixe LOG_ARCHIVE_MIN_SUCCEED_DEST pour archiver dans des petits nombres de destinations.
Il faut utiliser l'attribut REOPEN du paramètre LOG_ARCHIVE_DEST_n pour spécifier si et ou ARCn devait tenter pour réarchiver dans une destination échoué suivant l'erreur. REOPEN s'applique pour toutes les erreurs, non seulement au erreurs OPEN.
REOPEN=n, fixe le nombre minimum de secondes avant ARCn devrait essayer pour rouvrir une destination défaillie. La valeur par défaut de n est 300 secondes. Une valeur 0 est la même d'enlever l'attribut REOPEN ; ARCn ne tentera pas d'archiver après la défaillance. Si on ne spécifie pas la clé REOPEN, ARCn recommencera plus à ouvrir la destination si erreur.
On ne peut pas utiliser REOPEN pour spécifier le nombre de tentative que ARCn devrait faire pour rejoindre et transférer les fichiers redo archivés.
Quand on spécifie REOPEN pour une destination OPTIONAL, Oracle peut mettre à jours les journaux s'il y'a erreur. Si on spécifie REOPEN pour une destination MANDATORY, Oracle décline la base de production quand il n'arrive pas à l'archiver. ans cette situation, on considère les options suivantes :
Quand on utilise le mot clé REOPEN on' a :
II.9. Trace du processus d'archivage
Les processus Background écrivent toujours dans les fichiers de trace quand c'est nécessaire. Dans le cas du processus d'archive, nous pouvons contrôler la sortie produite dans le fichier de trace, en fixant le paramètre d'initialisation LOG_ARCHIVE_TRACE par un niveau de trace. Cette valeur peut être spécifie comme suit :
Les processus Background écrivent toujours dans les fichiers de trace quand c'est nécessaire. Dans le cas du processus d'archive, nous pouvons contrôler la sortie produite dans le fichier de trace, en fixant le paramètre d'initialisation LOG_ARCHIVE_TRACE par un niveau de trace. Cette valeur peut être spécifie comme suit :
Nous pouvons combiner les niveaux de tracement en spécifiant une valeur égale à la somme des niveaux individuellement. Par exemple :
Produit un fichier trace de niveau 8 et 4. Nous pourrons fixer différentiels valeurs pour une base primaire et une base standby.
La valeur par défaut du paramètre LOG_ARCHIVE_TRACE est 0. A ce niveau, Le processus archivelog génère les alertes appropriées.
On peut modifier la valeur de ce paramètre dynamiquement en utilisant la commande ALTER SYSTEM. La base doit être montée mais non ouverte. Par exemple :
A cette manière, la modification prend effet au démarrage de la base à la prochaine opération d'archivage.
II.10. Informations sur les vues des fichiers redo archivés
On peut afficher des informations concernant les fichiers redo archivés en utilisant :
II.10.1. Les vues dynamique
Il existe plusieurs vues qui nous donnent des informations sur les fichiers redo archivés comme :
Par exemple pour savoir le fichier redo qui doit être archivé, on lance la commande suivante :
Pour Savoir si la base est en mode ARCHIVELOG :
II.10.2. La commande ARCHIVE LOG LIST
La commande ARCHIVE LOG LIST affiche des informations sur las archives de l'instance connecté. Par exemple :
En cours, Je cite les autres options de la commande ARCHIVE LOG
III. Le Redo Log Buffer
En cours. Il n y'a pas beaucoup de chose à dire sur le
redo log buffer. Par contre je parlerai un peit peu sur les latchs.
IV. Checkpoint
Le mot Checkpoint signifie la synchronisation des données modifiées en mêmoire avec les fichiers de données dans la base.
Par intervalle, le fait d'écrire les données modifiées dans les fichiers de données entre les checkpoints assure la disponibilité d'une quantité de mémoire, qui améliorera les performances pour trouver de la mémoire libre pour les opérations suivantes. Le mécanisme d'écritures des blocs modifiés dans le disque n'est pas synchronisé avec le commit des transactions.
Le checkpoint doit s'assurer que toutes les modifications des tampons dans la cache sont réellement écrites dans les fichiers de données correspondants.
Le checkpoint se réalise sous quatre types d'évènements :
Le checkpoint doit être rompus dans deux cas spécifiques :
Quand LGWR effectue cette tâche, il ne peut pas faire son travail normalement, qui consiste à écrire les transactions dans les fichiers redo. Un process spécifique CKPT doit être utiliser pour liberer le LGWR de cette tâche. A partir de la version Oracle8 le process CKPT démarre automatiquement.
Le mécanisme de checkpoints présente un dilemme pour les dba Oracle, qui doivent trouver un point de compromis entre une performance global de l'instance et la rapidité de la restauration. La durée de restauratement est directement lié à la frequence des checkpoints.
Plus il y'a de checkpoints, plus la restauration est rapide. La restauration dépend de la quantité écrite dans le fichier redo depuis le dernier checkpoint.
Quand une restauration est nécessaire suite à un crash de l'instance, seulement les transactions écrites depuis le dernier checkpoint qui sont appliqués. Suivant le contexte, on a le choix entre la sécurité avec des checkpoints fréquents et un temps de restauration court ou une performance globale de l'instance avec des checkpoints moins fréquents. Normalement la majorité préfère la performance, car elle représente l'activité majeure dans une base de production.
Il y'a deux types de checkpoints :
Le checkpoint normal met à jours les fichiers de contrôle et les entêtes des fichiers de données
Le checkpoint incremental met à jours seulement le fichier de contrôle.
IV-A. Les paramètres de checkpointIV-A-1. Avant la 10g
Voir l'article sivant : Avant la 10g
IV-A-2. Le paramètre FAST_START_MTTR_TARGET
Dans 10g, Oracle à introduit le Conseiller Calibrage des Fichiers Redo qui est recommandé pour tailler les fichiers redo en limitant les log switchs démesurés, les checkpoints excessifs et incomplète, le problème d'archive, la performance du DBWR et les E/S excessif du disque. Dans 10g on peut spécifier à travers le paramètre FAST_START_MTTR_TARGET seulement la durée de la restauration de la base suite à un crash.
La fixation de ce paramètre déclenchera le conseiller calibrage des fichiers redo et proposera la taille optimale pour les fichiers redo. On peut utiliser la valeur en Mega de la colonne OPTIMAL_LOGFILE_SIZE dans la vue V$INSTANCE_RECOVERY pour reconstruire les groupes des fichiers redo :
V-B. En cours
Ici c'est plus interessant, je vais détaillé la structure interne de la file d'attente Checkpoint,
qui va me servir pour un prochain article sur la structure interne du buffer cache.
V. Reglages des fichiers redo et du redo log bufferV-A. log file switch completion
Dans Oracle 10g, L'événement d'attente log file switch completion fait partie
de la classe Configuration. Il faut toujours tenir compte des considérations suivantes :
Si une session passe beaucoup de son temps de traitements à attendre dans l'événement
log file switch completion, c'est parce que la taille des fichiers redo sont petites par rapport à la quantité d'entrées redo qui se reproduisent, provoquant de nombreux log switch. La session Oracle attend constamment que le processus LGWR termine l'écriture dans le fichier redo en cours et d'ouvrir de nouveau un autre fichier redo.
Le temps d'attente de l'évènement log file switch completion peut être diminuer ou éliminer en réduisant le nombre de log switch. Cela signifie qu'on a besoin de créer de nouveaux groupes de fichiers redo assez grand et supprimer les anciens groupes. Un fichier redo assez grand diminuera le nombre de switch log et les checkpoints classiques qui sont très coûteux.
Quelle est la taille du fichier redo ? La réponse dépend de la taille du fichier redo en cours, le taux actuel de switch log et l'objectif fixé en nombre de log switch par heure pendant les traitements. Pour trouver la fréquence des log switch en utilise la requête données dans la section log buffer space. Si notre objectif est de 4 fichiers redo par heure au lieu de 60 et que la taille du fichier redo en cours est de 20M, alors le nouveau fichier redo devrait avoir une taille de 300M (60*20M/4).
V-B. log file switch (checkpoint incomplete)
Dans 10g, l'événement d'attente log file switch (checkpoint incomplete) fait partie des classes Configuration. Il faut toujours tenir compte des considérations suivantes :
Le log file switch (checkpoint incomplete) et le log file switch completion sont deux évènements très proches et partagent la même cause, c'est à dire, la taille des fichiers redo sont assez petites par rapport à la quantité des entrées redo qui sont produites. Quand on a l'un de ces évènements, normalement on a l'autre. Dans ce cas, les processus foreground attendaient le processus DBWR au lieu d'attendre le processus LGWR. Cela arrive, quand une application produit beaucoup d'entrées redo, tellement que le processus LGWR n'arrive plus à recycler les fichiers redo car le DBWR n'a pas encore fini de copier les blocs modifiés. Le processus LGWR ne peut pas sur écrire ou passer le prochain fichier redo, car le checkpoint est incomplet. La solution est d'augmenter la taille des fichiers redo et d'ajouter d'autres groupes. V-C. L'attente de l'évènement log file sync
Dans 10g, l'événement d'attente log file sync fait partie des classes Configuration. Il faut toujours tenir compte des considérations suivantes :
Oracle enregistre les transactions et les blocs modifiés dans le log buffer. Le processus LGWR est responsable de liberer la place dans le log buffer en écrivant le contenu du log buffer dans les fichiers redo :
Les écritures initiées par des validations ou des annulations utilisateurs sont connues sous le nom d'écritures synchrone ; il se peut qu'un processus utilisateur effectue une grande transaction qui génère beaucoup d'entrées redo ce qui déclenchera le processus LGWR à exécuter des écritures background, mais la session de l'utilisateur n'attendra jamais que les écritures background se terminent. Toutefois, au moment où la session utilisatrice valide ou annule sa transaction et le paramètre _WAIT_FOR_SYNC est à TRUE, le processus poste le LGWR et attends dans l'événement log file sync pour que le processus flashe les entrées redo en cours, inclus le marqueur commit, dans les fichiers redo. Durant la synchronisation de ces logs, le processus LGWR attend en faveur d'une écriture synchrone pour terminer dans l'événement log file parallel write tandis que la session utilisatrice attends en faveur d'un processus de synchronisation pour terminer dans l'événement log file sync.
Une fois le process entre dans l'attente log file sync, il y'aura deux possibilités pour sortir. L'un, est quand le process foreground est posté par LGWR quand la synchronisation log est achevée. L'autre, est quand l'attente à fait une pause ( typiquement en 1 seconde), at which point le process foreground vérifie le log SCN courant pour déterminer si ces commit ont était effectué dans le disque. Si c'est arrivé, le process continue le traitement, sinon le process re-entre l'attente.
Typiquement, L'attente log file sync est un événement sans incident. Il est bref et à peine perceptible par l'utilisateur final. Pourtant, une multitude de ces attentes peut contribuer à des temps de réponses longues et trace des statistiques dans les vues V$SYSTEM_EVENT et V$SESSION_EVENT. Utiliser cette requête pour trouver les sessions en cours qui passent la plupart de leurs traitements à attendre dans l'événement log file sync depuis l'ouverture de la session. Evaluer le TIME_WAITED avec USER_COMMIT et HOURS_CONNECTED. Pour découvrir qui exécute beaucoup de commit entre deux points spécifiques dans le temps, on peut calculer le delta en utilisant l'exemple suivant :
V-A-1. fréquence très élevée des validations
Parmi les causes de l'attente log file sync est la fréquence très élevée des validations
(commit). Il faut trouver si la session qui passe plus de temps dans l'événement
log file sync appartient à un batch ou à un processe OLTP ou si c'est un middle-tier
(comme Tuxedo, Weblogics, etc.)
Si la session appartient à un process batch, il doit être validé à chaque modification
de la base à l'intérieur d'un loop. Découvrir le nom du module et demander au développeur
e revoir dans leurs codes si les nombres de commit peut être diminués.
C'est un problème d'applications, et la solution est simplement d'éliminer les validations non nécessaires et réduire la fréquence des validations.
Certains developpeurs d'applications ont appris que s'ils valident rarement,
les jobs devrait s'échouer suite au manque d'espace dans les segements d'annulations,
t on peut être appelé à minuit.
Introduire des validations supplémentaire peut créer d'autres problèmes, parmis eux, la fameuse ORA-01555: l'erreur snapshot too old car l'annulation (ou undo) des données peuvent être sur écrite. Une frequence de commit trops elevé augmente aussi le temps système qui est associé avec le démarrage et la fin des transactions. Au début de chaque transaction, Oracle assigne un segement d'annulation (appelé segement d'annulation imposé) et mets à jours la table de transaction dans l'entête du segement d'annulation. la table de transaction doit être aussi mis à jours à la fin de chaque transactions, suivi par une validation de l'activitée de netoyage. Mettre à jours l'entête du segement d'annulation doit aussi être enregistré dans le log buffer car le bloc à été modifié. Pourtant, le fait de valider à la fin d'une unité de travail resoudera le problème. Le commit dans un loop à besoin d'être enlevé de telle façon que le commit d'un travail se fasse à la fin.
Si la session qui passe beaucoup de temps dans l'événement log file sync est une connexion persistance d'une couche middle-tier, alors c'est un cas difficile car il servit plusieurs utilisateurs frontaux. On doit tracer la session avec l'événement 10046 et observer le comportement de l'application. Chercher l'événement log file sync dans le fichier trace. Ils nous donneront une idée sur la fréquence des validations. Alternativement, on peut creuser les fichiers redo par le Logminer. Cela montrera le comportement des validations dans le système.
Dans une base OLTP, on observe normalement, un temps d'attente élevé du log file sync au niveau système (V$SYSTEM_EVENT) mais pas au niveau session. Le temps d'attente élevé au niveau système doit être mené par des petites transactions des sessions OLTP qui sont se connecte et se déconnecte activement dans la base. Si c'est notre scénario, le seule chose que nous pourrons faire est d'assurer un circuit stable d'E/S pour le process LGWR. Cela inclus l'utilisation les E/S/ asynchrones et mettre les fichiers redo dans des périphériques RAW ou un équivalent, comme Veritas Quick I/O, cela est servi par des contrôleurs E/S dédié ou mieux encore, utiliser des disques performants pour les fichiers redo. V-A-2. E/S lent
Examiner la vue V$SYSTEM_EVENT comme il suit pour découvrir le temps d'attente moyen de LGWR (événement log file parallel write). Le temps d'attente moyenne de 10ms (1cs) ou inférieur est généralement acceptable.
Un débit trop élevé d'E/S dans un système peut améliorer la moyenne du temps d'attente des évènements log file sync et log file parallel write. Pourtant, ce n'est pas une excuse de ne pas régler l'application si elle est mal conçue et valide fréquemment. On doit tenter de bien chercher la couche de la base et l'E/S du sous-système, peut être-il est difficile de traiter avec un groupe d'application ou une application third-party. Toutefois, parce qu'est une application third-party ne donne pas au vendeur le droit lancer des codes bric-à-brac dans la base. A savoir qu'on ne peut pas résoudre ce genre de problème applicatif. Chaque modification effectuée par notre soin dans la base donnera l'impression à l'utilisateur que c'est un problème de la base.
Il y'a plusieurs choses qu'on peut fournir avec l'aide de l'administrateur système concernant l'attente log file sync en augmentant le débit d'E/S des fichiers redo. Cela inclus l'utilisation des connexions fibre optique (FC) au bases sous SAN (storage area network), Ethernet gigabit (Gig-E) ou des connexions en Bande Infini à la base sous NAS (network attached storage), SCSI utltrawide ou des connexions FC à au bases sous DAS (direct attached storage) ; reseaux privés ; switches à haut-vitesse ; contrôleurs d'E/S dédié ; E/S asynchrones ; Placer les fichiers redo dans des péréphiriques RAW et lier le LUN dans RAID 0 ou 0+1 à la place de RAID 5, et ainsi de suite.
V-A-3. Log Buffer trop grand
Suivant l'application, un log buffer surdimensionné (plus grand que 1M) peut étendre les attentes log file sync. Un log buffer large réduit le nombre d'écritures background et permet au processe LGWR d'être paresseux et provoque beaucoup d'entrées redo de s'accumuler dans le log buffer. Quand un processe valide, le temps d'écriture synchrone ne devrait pas être long car le processe LGWR à besoin de copier beaucoup d'entrées redo. La taille de notre log buffer ne devrait pas être petit, cela provoquerai les sessions à servir l'évènement log buffer space plus ou moins
grand ce qui prolongera les attentes log file sync. D'une part, on veut un log buffer assez large pour faire face aux demandes d'espaces du log buffer durant la génération explosive des redo, surtout immédiatement après un log switch. D'autre part, on veut un log buffer assez petit pour augmenter les écritures background et réduire le temps d'attente du log file sync. Pour satisfaire les deux demandes, c'est le paramètre _LOG_IO_SIZE, qui est par défaut le 1/3 du LOG_BUFFER ou 1mb, peu importe si c'est inférieur. C'est l'un des seuils qui signale au process LGWR de commencer à écrire. En d'autres mots, on peut avoir un log buffer assez large, mais un _LOG_IO_SIZE assez petit devrait augmenter les écritures background, qui à la suite réduit le temps d'attente log file sync. Beaucoup d'activités de LGWR mat une lourde charge dans les latches redo copy et redo writing. Voir l'événement d'attente log file parallel write.
Par défaut, le paramètre _LOG_IO_SIZE est réduit à 1/6 de la taille du LOG_BUFFER dans Oracle 10g. Car la valeur par défaut du paramètre _LOG_PARALLELISM_MAX est à 2 quand le paramètre COMPATIBLE est fixé à 10.0 ou plus. La valeur par défaut de _LOG_IO_SIZE dans Oracle 10g se calcule en divisant la taille du LOG_BUFFER avec la taille de bloc du journal (LEBSZ) et la valeur de kcrfswth, comme ici :
V-D. log file parallel write
L'évènement d'attente log file parallel write à trois paramètres : fichiers, blocs et demandes. Dans 10g cette évènement fait partie des classes des attentes E/S systèmes. Il faut tenir compte des ces trois clés s'il y a un évènement d'attente log file parallel write.
L'événement d'attente log file parallel write concerne seulement le process LGWR. Quand il est temps d'écrire, Le process LGWR écrit le redo buffer dans les fichiers de journalisation en ligne en lançant des séries d'appels écriture système dans l'OS. Le process LGWR attend en faveur des écritures pour terminer l'événement d'attente log file parallel write. Le process LGWR cherche les blocs redo pour les écrire toutes les trois secondes, pendant le commit, pendant le rollback, quand le seuil _LOG_IO_SIZE est atteint, quand 1M d'entrée redo est dans le log buffer et quand c'est signalé par le process DBWR.
Quoique les sessions utilisateurs n'influencent pas l'événement d'attente log file parallel write, elles peuvent avoir un impact en ralentissant le process LGWR. Un process LGWR lent, peut exalter les attentes log file sync, à laquelle les sessions utilisateurs attend durant les commits ou les rollbacks. Les sessions utilisateurs n'obtiendront pas une reconnaissance complète d'un commit ou d'un rollback jusqu'à ce que le LGWR à terminer son écriture.
Les statistiques clés de la base à tenir en compte sont TIME_WAITED et AVERAGE_WAIT des évènements d'attentes log file parallel write et log file sync :
Si l'attente de l'évènement log file parallel write est plus grand que 10ms, cela indique normalement un débit lent d'E/S. Activer les écritures asynchrones si les redo logs sont dans des devices raw et si l'OS supporte les E/S asynchrones. Malheureusement, on ne peut pas utiliser plus qu'un seul process LGWR. Dans ce cas, il est nécessaire de ne pas surcharger Le point de montage et le contrôleur ou se trouve les fichiers de journalisation. Déplacer les fichiers de journalisation dans des disques rapides peut aussi aider. Il est fortement conseillé d'éviter de mettre les redo logs dans les disques RAID5.
En plus des améliorations du débit d'E/S, on peut diminuer la quantité des entrées redo. Si possible, utilisez l'option NOLOGGING. Les indexes devrait être crées ou reconstruis avec l'option NOLOGGING. Les opérations CTAS doivent utiliser aussi cette option.
Une fréquence basse de validation aux détriments de l'usage des segments d'annulations fourni aussi quelques soulagements. Une fréquence élevée de validation provoque le process LGWR d'être hyperactif et quand il est couplé avec débit d'E/S assez lent devrait seulement exagérer les attentes du log file parallel write. L'application qui doit traiter un grand ensemble de données dans un loop et valide chaque modification, provoquera le log buffer d'être flashé fréquemment. Dans ce cas, il faut modifier l'application pour qu'il valide moins fréquemment. Il peut y avoir aussi plusieurs sessions courtes qui se connecte à la base, exécutant des opérations DML rapide, et se déconnecte. Dans ce cas, le modèle de l'application doit être revu. On peut trouver ailleurs celui qui valide le plus fréquemment avec la requête suivante :
Une autre évidence des validations excessive est le gaspillage élevé des redo.
Vérifier le job scheduler pour voir si une sauvegarde à chaud à été lancé durant les heures de pointe. Il est capable de créer une grande quantité d'entrées redo, qui à la suite augmente l'attente du log file parallel write. Une sauvegarde à chaud devrait être lancé en dehors des heures de pointe.
A la fin, Il faut faire attention de ne pas charger le LGWR avec de nombreux entrées redo en même temps. Cela peut arriver avec un grand log buffer car le seul 1/3 est aussi grand et garde plus d'entrées redo. Quand le seuil 1/3 est atteint, le process LGWR accompli l'écriture background s'il n'est pas encore activé. Et la quantité des entrées redo doit être trop pour le process LGWR de traiter en une seule fois, provoquant le prolongement des attentes log file parallel write. Ainsi, l'idée est de verser les écritures LGWR. Cela peut être fait en diminuant le seuil 1/3, qui est contrôler par le paramètre d'initialisation _LOG_IO_SIZE. Par défaut _LOG_IO_SIZE est 1/3 du LOG_BUFFER ou 1MB, peu importe si c'est moins, exprimé en blocs de log. Requêter X$KCCLE.LENSZ pour avoir la taille du bloc d'un journal. Typiquement, c'est 512 bytes. Par exemple, si LOG_BUFFER est 2097152 bytes (2MB), et la taille du bloc journal est 512 bytes, alors la valeur par défaut de _LOG_IO_SIZE est 1365 de blocs de journal utilisés. A cette taille, le process LGWR devient paresseux et écrit normalement seulement à la fin des transactions (écritures synchrones) ou quand il se réveille de sa pause de 3 secondes. On devrait mettre _LOG_IO_SIZE à 64K. De cette façon, on peut calmer d'avoir un grand log buffer pour accorder les points de transitions pour l'espace tampon après les checkpoints, mais les écritures devraient démarrer quand il y'a 64K d'entrées redo dans le tampon, en supposant qu'il ni y a aucune validation ou annulation d'un utilisateur, et le LGWR en sommeil n'a pas écoulé son temps durant cette période.
On peut utiliser la requête suivante pour trouver le nombre moyen de blocs redo log par écriture et le moyen de la taille d'E/S LGWR en bytes :
VI. Le LOGMINNER
Ca sera un autre article. Je pense qu'il existe déja
VI-A. IntroductionVI-B. Configuration du LogminerVI-C. Utilisation du LogminerVI-D. La vue V$LOGMNR_CONTENTSVI-E. DBMS_LOGMNR.START_LOGMNRVIII. Dump des fichiers Redo
Les informations dans les fichiers redo sont souvent très utile pour diagnostiquer les problèmes de corruption.
On utilise les commandes suivantes :
Cette commande nécessite le privilège système ALTER SYSTEM. La base peut être en mode mount, nomount ou open quand la commande est lancé. Un fichier redo en ligne ou archivé peut être déchargé. Il est possible de faire un dump d'un fichier d'une autre base, tant que l'OS est le même.
La sortie de la commande est mise dans le fichier trace de la session.
Les differents façons pour faire un dump du fichier redo sont :
A. Dump basé sur le DBA (Data Block Address)Cela, déchargera tous les enregistrements redo dans un rangée de
blocs de données specifié par file# et bloc#..
A partir de SQL, en lance la commande suivante :
Exemple:
B. Dump basé sur le RBA (Redo Block Address)
Ici, on décharge tous les enregistrements redo entre deux adresses redo spécifiés par
un numéro de séquence et un numéro de bloc.
Example:
C. Dump basé sur le temps
Cette option devrait provoquer la décharge des enregistrements redo crées entre
deux dates.
Pour décharger le fichier redo suivant les dates, on utilise la commande suivante :
Par exemple:
time = (((((yyyy - 1988)) * 12 + mm - 1) * 31 + dd - 1) * 24 + hh) * 60 + mi) * 60 + ss;
D. Dump basé sur la couche et l'opcode.
LAYER and OPCODE sont utilisés pour décharger tous les enregistrements d'un type particulier.
Depuis la commande SQL :
Par exemple:
E. Dump des informations de l'entête du fichier
Cette commande décharge les informations des entêtes de tous les fichiers redo en ligne.
A partir de SQL :
La commande décharge les entêtes de tous les fichiers journaux

* DUMP OF LOG FILES: 3 logs in database
La ligne suivante montre que la base à 3 fichiers de journalisation.
* LOG FILE #1: (name #3) D:\ORACLE\PRODUCT\10.2.0\ORADATA\B10G2\REDO01.LOG
C'est le nom du fichier de journalisation avec le chemin complet.
* Thread 1 redo log links: forward: 2 backward: 0
siz: 0x19000 seq: 0x00000053 hws: 0x4 bsz: 512 nab: 0xffffffff flg: 0x8 dup: 1
Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.00315ef2
Low scn: 0x0000.0031b9a8 10/23/2005 00:40:37
Next scn: 0xffff.ffffffff 01/01/1988 00:00:00
Ces informations se trouve dans le fichier de contrôle.
Ici on'a deux informations intéressantes pour calculer la taille du fichier redo : siz et bsz.
Bsz est la taille d'un bloc et siz est le nombre de blocs dans le fichier redo.
Dans cette exemple la taille du fichier redo exacte est 52429312 (taille OS, on peut le verifier par les commandes OS comme ls sous unix ou dir sous dos).
D'après le fichier trace la taille du fichier redo est egale à siz x bsz = 102400 x 512 = 52428800 (car 0x19000 est égale à 102400 en décimal). Et on remarque qu'il manque un bloc 52429312 - 52428800 = 512 . Tout simplement le bloc manquant est celui de l'entête du fichier redo qui contient des informations OS. Enfin, la taille exacte du fichier est (siz + 1) x bsz.
seq: 0x00000053 c'est le numéro de sequence du fichier redo, en décimal c'est 83=5*16+3.
hws: 0x4 c'est header write seq#
nab: 0xffffffff le prochain bloc disponible (next available block)
flg: 0x8 c'est le type de fichier (ici un fichier redo en ligne). Le drapeau peut prendre les valeurs suivantes :
Low scn: 0x0000.0031b9a8 10/23/2005 00:40:37 c'est le SCN quand le fichier redo à commuter en Next scn: 0xffff.ffffffff 01/01/1988 00:00:00 . next scn est soit égale à low scn du prochain fichier redo ou 0xffff.ffffffff s'il est encore en ligne.
Dans la section FILE HEADER on'a :
Compatibility Vsn = 169869568=0xa200100 veut dire une base en 10.2.01
Db ID=1483236283=0x586863bb
Control Seq=2084=0x824, c'est le numéro de séquence du fichier de contrôle, ce numéro est nécessaire pour trouver le bon fichier de contrôle suite à une restauration.
File Type=2 LOG c'est le type du fichier, le type 2 veut dire un fichier redo.
descrip:"Thread 0001, Seq# 0000000083, SCN 0x00000031b9a8-0xffffffffffff" C'est un texte en ASCII juste une aide pour le deboguage.
thread: 1 nab: 0xffffffff seq: 0x00000053 hws: 0x4 eot: 1 dis: 0
thread : le numéro de thread pour ce fichier redo nab : prochain bloc disponible seq : le numéro de sequence du fichier redo eot : indique si c'est le dernier log (End Of Thread). Il prend les valeurs suivantes :
dis : DISabled - Vrai si le thread est désactivé à la fin de ce log.
F. Dump du fichier redo en entier
A partir de SQL on peut lancer la commande suivante :
Par exemple:
IX. Les fichiers redo et les sauvegardesX. AppendiceIX.1. RBA
Les entrées recentes dans le redo thread d'une instance oracle ont une adresse appelé
RBA (Redo Byte Address) qui est constitué de trois parties :
Les RBA ne sont pas nécessairement unique dans leurs thread, puisque le numéro de sequence
du fichier journal peut être mis à 1 dans tous les thread si la base est ouverte
avec l'option RESETLOGS.
Les RBA sont utilisés dans les cas suivants :
En ce qui concerne les blocs modifiés dans le buffer cache, le low RBA est l'adresse redo de la première modification qui a été appliqué au bloc depuis le dernier nettoyage. Le High RBA est l'adresse redo de la plus recente modification appliqué au bloc.
Les tampons modifiés sont conservés dans la file d'attente checkpoint du buffer cache dans l'ordre du low RBA. Le checkpoint RBA est le point à partir duquel DBWn à écrit des tampons depuis la file d'attente checkpoint si le checkpointing incremental à été activé - autrement il est le RBA du dernier checkpoint du thread complet. Le checkpoint RBA est copié dans le record checkpoint progress du fichier de contrôle par le checkpoint heartbeat une fois chaque 3 secondes. La restauration de l'instance, quand c'est nécessaire, commence depuis le checkpoint RBA enregistré dans le fichier de contrôle. Le target RBA est le point à partir duquel DBWn devrait chercher pour avancer le checkpoint RBA pour satisfaire les objectices de la restauration de l'instance.
Le on-disk RBA est le point à partir duquel LGWR à vider le redo thread dans les log files en ligne. DBWn ne doit pas écrire un bloc dans lequel le high RBA est au-dela du on-disk RBA. Autrement la restauration de la transaction (rollback) ne pourrais pas être possible, car le redo nécessaire pour annuler la modification est toujours dans le même redo record comme le redo de la modification elle-même.
Le terme sync RBA est parfois utilisé pour indiquer le point à partir duquel LGWR est requis pour synchroniser le thread. Pourtant, ce n'est pas un RBA complet - seulement le numéro du bloc redo est utilisé à ce point.
Le low et high RBA pour les tampons modifiés peuvent être vue dans X$BH. (Il y'a aussi un RBA de restauration qui est utilisé pour enregistrer une restauration d'un bloc en cours ou partiel par PMON). Le incremental checkpoint RBA, le target RBA et le on-disk RBA peuvent aussi être vues dans X$KCCCP. Le checkpoint RBA d'un thread complet paut être vue dans X$KCCRT.
IX.2. RDBA et DBA
Chaque bloc oracle est identifié par un numéro unique qui est la combinaison
d'un numéro de fichier et d'un numéro de bloc. Cette combinaison est representée
par RDBA (Relative Data Block Address).
Pour connaître le RDBA du bloc 7 contenu dans le fichier 5
Pour trouver la valeur en hexadecimal de 20971527 :
Donc, 1400007 est le RDBA du bloc de données 7 qui se trouve dans le fichier 5.
Ce document est issu de http://www.developpez.com et reste la propriété exclusive de son auteur.
La copie, modification et/ou distribution par quelque moyen que ce soit est soumise à l'obtention préalable de l'autorisation de l'auteur.
|