



I. Introduction▲
Oracle utilise les fichiers redo pour être sûr que toute modification effectuée par un utilisateur ne sera pas perdue s'il y a défaillance du système. Les fichiers redo sont essentiels pour les processus de restauration. Quand une instance s'arrête anormalement, il se peut que certaines informations dans les fichiers redo ne soient pas encore écrites dans les fichiers de données. Oracle dispose les journaux redo en groupes.
Les fichiers redo doivent être placés sur des axes différents et des disques très rapides.
Chaque groupe a au moins un fichier redo. On doit avoir au minimum deux groupes distincts de fichiers redo (aussi appelés redo threads), chacun contient au minimum un seul membre. Car, si l'on n'a qu'un seul fichier redo, Oracle écrasera ce fichier redo et on perdra toutes les transactions.
Chaque base de données à ses groupes de fichiers redo. Ces groupes, multiplexés ou non, sont appelés instance du thread de redo. Dans des configurations typiques, une seule instance de la base accède à la base Oracle. Ainsi, seulement un thread est présent. Dans un environnement RAC, deux ou plusieurs instances accèdent simultanément une seule base de données et chaque instance à son propre thread de redo.

I-A. Contenu du fichier redo▲
Les fichiers redo sont remplis par des enregistrements redo. Un enregistrement redo, aussi appelé une entrée redo, est composé d'un groupe de vecteurs de changements, qui est une description d'un changement effectué à un bloc de la base. Par exemple, si l'on modifie la valeur d'un salaire dans la table employé, on génère un enregistrement redo qui contient des vecteurs de changements décrivant les modifications sur le bloc du segment de données de la table, le bloc de données du segment undo et la table de transaction des segments undo.

Les entrées redo enregistrent les données que l'on peut utiliser après pour reconstruire tous les changements effectués sur la base, segments undo inclus. De plus, le fichier redo protège aussi les données d'annulation. Quand on restaure la base en utilisant les données redo, la base lit les vecteurs de changements dans les enregistrements redo et applique le changement aux blocs appropriés.
Les enregistrements redo sont mis d'une façon circulaire dans le buffer redo log de la mémoire SGA. Et ils sont écrits dans un seul fichier redo par le processus LGWR. Dès qu'une transaction est validée, LGWR écrit les enregistrements redo de la transaction depuis le buffer redo log du SGA vers le fichier redo, et attribut un SCN pour identifier les enregistrements redo pour chaque transaction validée et ce, seulement lorsque tous les enregistrements redo associés à la transaction donnée sont sans incident sur le disque dans les fichiers redo en ligne et que le processus utilisateur a notifié que la transaction a été validée.

Les enregistrements redo peuvent aussi être écrits dans le fichier redo avant que la transaction correspondante soit validée. Si le buffer redo log est plein ou une autre transaction a été validée, LGWR vide toutes les entrées redo du buffer redo log dans le fichier redo, bien que certains enregistrements redo ne devrait pas être validés. Si nécessaire, oracle peut annuler ces changements.
I-B. Comment Oracle écrit dans les fichiers redo▲
La base oracle exige au minimum deux fichiers redo.
LGWR écrit dans les fichiers redo d'une façon circulaire. Quand le fichier redo courant est plein, LGWR commence à écrire dans le prochain fichier redo disponible. Quand le dernier est plein, LGWR commence à écrire dans le premier fichier redo.
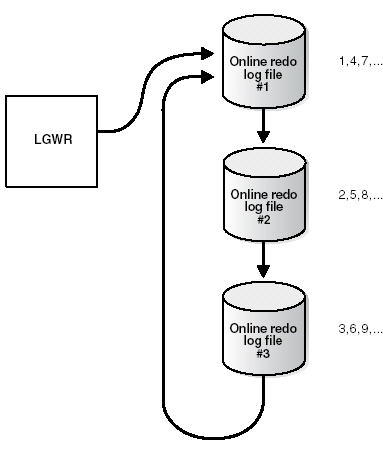
- Si l'archivage est désactivé (la base en mode NOARCHIVELOG), un fichier redo plein est disponible après que les changements enregistrés dedans sont écrits dans les fichiers de données.
- Si l'archivage est activé (la base est en mode ARCHIVELOG), un fichier redo plein est disponible pour le processus LGWR après que les changements effectués dedans sont écrits dans les fichiers de données et était archivé.
Les fichiers redo Active (Courant) et Inactive
Oracle utilise un seul fichier redo à la fois pour stocker les enregistrements redo depuis le redo log buffer. Le fichier redo dont le processus LGWR est en train d'écrire dedans est appelé le fichier redo courant.
Les fichiers redo nécessaires à la restauration de la base sont appelés les fichiers redo actifs. Les fichiers redo qui ne sont pas nécessaires à la restauration s'appellent les fichiers redo inactifs.
Si on a activé l'archivage (mode ARCHIVELOG), alors la base ne peut pas réutiliser ou réécrire dans le fichier redo en ligne tant que l'un des processus ARCn n'a pas archivé ses contenus. Si l'archivage est désactivé (mode NOARCHIVELOG), alors quand le dernier fichier redo est plein, LGWR continue en sur écrivant le premier fichier actif disponible.
Les Logs Switchs et les numéros de séquence du journal
Un log switch est le point où la base arrête d'écrire dans l'un des fichiers redo en ligne et commence à écrire dans un autre. Normalement, un log switch survient quand le fichier redo courant est complètement rempli et il doit continuer à écrire dans le fichier redo suivant. Pourtant, on peut configurer les logs switchs pour qu'ils se reproduisent à intervalles réguliers, sans soucier si le fichier redo en cours est complètement rempli. On peut aussi forcer les log switch manuellement.
Oracle assigne à chaque fichier redo un nouveau numéro de séquence chaque fois qu'un log switch arrive et que le processus LGWR commence à écrire dedans. Quand oracle archive les fichiers redo, le fichier archivé garde le numéro de séquence du journal. Le fichier redo recyclé, fournit le prochain numéro de séquence du journal disponible.
Chaque fichier redo en ligne ou archivé est identifié uniquement par son numéro de séquence (log sequence).
Durant un crash, l'instance ou une restauration media , la base applique proprement les fichiers redo dans un ordre croissant en utilisant le numéro de séquence du fichier redo archivé nécessaire et des fichiers redo.
II. Informations sur les fichiers redo▲
Les vues V$THREAD, V$LOG, V$LOGFILE et V$LOG_HISTORY fournissent des informations sur les fichiers Redo.
La vue V$THREAD donne les informations sur le fichier redo en cours.
SQL> desc v$thread
Nom NULL ? Type
----------------------------------------- -------- ------------
THREAD# NUMBER
STATUS VARCHAR2(6)
ENABLED VARCHAR2(8)
GROUPS NUMBER
INSTANCE VARCHAR2(80)
OPEN_TIME DATE
CURRENT_GROUP# NUMBER
SEQUENCE# NUMBER
CHECKPOINT_CHANGE# NUMBER
CHECKPOINT_TIME DATE
ENABLE_CHANGE# NUMBER
ENABLE_TIME DATE
DISABLE_CHANGE# NUMBER
DISABLE_TIME DATE
LAST_REDO_SEQUENCE# NUMBER
LAST_REDO_BLOCK NUMBER
LAST_REDO_CHANGE# NUMBER
LAST_REDO_TIME DATE
SQL> select * from v$thread;
TRD# STAT ENABLED GRPS INST OPEN CURRENT SEQ CHECKP CHECKP ENABLE ENABLE DISABLE DIS LAST LAST LAST LAST
REDO REDO REDO REDO
TIME GROUP# CHANGE TIME CHANGE# TIME CHANGE# TIME SEQ BLOCK CHANGE# TIME
---- ---- ------ ---- ---- ---- ------- --- ------- -------- ------- ------ ------- ---- ---- ------ ------- ---------
1 OPEN PUBLIC 3 b10g2 19/10/05 2 81 3201917 19/10/05 547780 01/09/05 0 81 3755 3203391 19/10/05La vue V$LOG donne les informations en lisant dans le fichier de contrôle au lieu de lire dans le dictionnaire de données.
SQL> desc v$log
Nom NULL ? Type
----------------------------------------- -------- -------------
GROUP# NUMBER
THREAD# NUMBER
SEQUENCE# NUMBER
BYTES NUMBER
MEMBERS NUMBER
ARCHIVED VARCHAR2(3)
STATUS VARCHAR2(16)
FIRST_CHANGE# NUMBER
FIRST_TIME DATE
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
------ ------- --------- ----- ------- --- ------ ------------- --------
1 1 41 52428800 1 NO INACTIVE 1867281 18/09/05
2 1 42 52428800 1 NO CURRENT 1889988 18/09/05
3 1 40 52428800 1 NO INACTIVE 1845207 18/09/05Pour voir les noms des membres d'un groupe on utilise la vue V$LOGFILE
SQL> desc v$logfile
Nom NULL ? Type
----------------------------------------- -------- ---------------
GROUP# NUMBER
STATUS VARCHAR2(7)
TYPE VARCHAR2(7)
MEMBER VARCHAR2(513)
IS_RECOVERY_DEST_FILE VARCHAR2(3)
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER IS_RECOVERY_DEST_FILE
------ ------- ------- ------------------- ---------------------
3 STALE ONLINE D:\ORACLE\PRODUCT\10.2.0\ORADATA\B10G2\REDO03.LOG NO
2 ONLINE D:\ORACLE\PRODUCT\10.2.0\ORADATA\B10G2\REDO02.LOG NO
1 STALE ONLINE D:\ORACLE\PRODUCT\10.2.0\ORADATA\B10G2\REDO01.LOG NOGROUP# est le numéro du groupe Redo Log.
STATUS prend la valeur INVALID si le fichier est inaccessible, STALE si le fichier est incomplet , DELETED si le fichier n'est plus utilisé et vide si le fichier est en cours d'utilisation.
MEMBER est le nom du membre Redo Log
À partir de la 10g on a une nouvelle colonne dans la vue V$LOGFILE : IS_RECOVERY_DEST_FILE. Cette colonne se trouve dans les vues V$CONROLFILE, V$ARCHIVED_LOG, V$DATAFILE_COPY, V$DATAFILE et V$BACKUP_PIECE, elle prend la valeur YES si le fichier a été créé dans la région de restauration flash.
SQL> select * from V$LOG_HISTORY;
RECID STAMP THREAD# SEQUENCE# FIRST_CHANGE# FIRST_TI NEXT_CHANGE# RESETLOGS_CHANGE# RESETLOG
---------- ---------- ---------- ---------- ------------- -------- ------------ ----------------- --------
1 567895614 1 1 547780 01/09/05 578189 547780 01/09/05
2 567900275 1 2 578189 01/09/05 596011 547780 01/09/05
3 567981823 1 3 596011 01/09/05 650604 547780 01/09/05
4 568027925 1 4 650604 02/09/05 684588 547780 01/09/05
5 568203418 1 5 684588 03/09/05 714521 547780 01/09/05
6 568233638 1 6 714521 05/09/05 752984 547780 01/09/05
7 568244091 1 7 752984 05/09/05 781475 547780 01/09/05
8 568245159 1 8 781475 05/09/05 803278 547780 01/09/05
9 568302950 1 9 803278 05/09/05 851785 547780 01/09/05
10 568324398 1 10 851785 06/09/05 886760 547780 01/09/05La vue V$LOG_HISTORY contient des informations concernant l'historique des fichiers redo à partir du fichier de contrôle. Le maximum que peut retenir la vue dépend du paramètre MAXLOGHISTORY.
La seule solution pour initialiser cette vue est de recréer le fichier de contrôle. Voir Fichiers de Contrôle ou utiliser CONTROL_FILE_RECORD_KEEP_TIME.
Dans cet exemple on a l'erreur oracle suivante :
kccrsz: denied expansion of controlfile section 9 by 65535 record(s)
the number of records is already at maximum value (65535)
krcpwnc: following controlfile record written over:
RECID #520891 Recno 53663 Record timestampOn voit que le problème vient de la section 9 ce qui veut dire LOG HISTORY
SQL> select * from v$controlfile_record_section where type='LOG HISTORY' ;
TYPE RECORDS_TOTAL RECORDS_USED FIRST_INDEX LAST_INDEX LAST_RECID
------------- ------------- ------------ ----------- ---------- ----------
LOG HISTORY 65535 65535 33864 33863 520892Ce qui montre que RECORD_USED a atteint le maximum autorisé RECORD_TOTAL.
La solution est de mettre le paramètre CONTROL_FILE_RECORD_KEEP_TIME à 0 dans le fichier d'initialisation ou utiliser la commande suivante :
SQL> alter system set control_file_record_keep_time=0;MAXLOGHISTORY augmente dynamiquement quand CONTROL_FILE_RECORD_KEEP_TIME est différent de 0, mais il ne dépasse jamais la valeur 65535.
Supposons que control_file_record_keep_time = 30 (30 jours) et qu'un fichier redo archivé soit généré toutes les 30 secondes.
Pour 30 jours, on aura 86400 journaux ce qui dépassera la valeur 65535. Pour corriger le problème, on met le paramètre control_file_record_keep_time à 0 et pour l'éviter on augmente la taille des fichiers redo.
III. Création des groupes et des membres redo▲
Pour créer un nouveau groupe de fichier redo ou un membre, on doit avoir le privilège système ALTER DATABASE. La base peut avoir au maximum MAXLOGFILES groupes.
III-A. Création des groupes de redo▲
Pour créer un nouveau groupe de fichiers redo, on utilise la requête ALTER DATABASE avec la clause ADD LOGFILE.
Par exemple :
ALTER DATABASE
ADD LOGFILE ('/oracle/dbs/log1c.rdo', '/oracle/dbs/log2c.rdo') SIZE 500K;Il faut spécifier le chemin et le nom complet pour les nouveaux membres, sinon ils seront créés dans le répertoire par défaut ou dans le répertoire courant suivant l'OS.
On peut spécifier le numéro qui identifie le groupe en utilisant la clause GROUP :
ALTER DATABASE
ADD LOGFILE GROUP 10 ('/oracle/dbs/log1c.rdo', '/oracle/dbs/log2c.rdo')
SIZE 500K;L'utilisation des numéros de groupes facilite l'administration des groupes de fichiers redo. Le numéro de groupe doit être entre 1 et MAXLOGFILES. Surtout ne pas sauter les numéros de groupes (par exemple 10, 20,30), sinon de l'espace dans les fichiers de contrôle sera consommé inutilement.
III-B. Création des membres de fichiers redo▲
Dans certains cas, il n'est pas nécessaire de créer complètement un groupe de fichiers redo. Le groupe peut déjà exister, car un ou plusieurs membres ont été supprimés (par exemple, suite à une panne d'un disque). Dans ce cas, on peut ajouter de nouveaux membres dans le groupe existant.
La base peut avoir au maximum MAXLOGMEMBERS membres.
Pour créer un nouveau membre de fichier redo d'un groupe existant, on utilise la commande ALTER DATABASE avec la clause ADD LOGFILE MEMBER. Dans l'exemple suivant, on ajoute un nouveau membre au groupe de redo numéro 2 :
ALTER DATABASE ADD LOGFILE MEMBER '/oracle/dbs/log2b.rdo' TO GROUP 2;Notez que le nom du fichier doit être indiqué, mais sa taille n'est pas obligatoire. La taille du nouveau membre est déterminée à partir de la taille des membres existants du groupe.
Quand on utilise ALTER DATABASE, on peut identifier alternativement le groupe cible en spécifiant tous les autres membres du groupe dans la clause TO, comme le montre l'exemple suivant :
ALTER DATABASE ADD LOGFILE MEMBER '/oracle/dbs/log2c.rdo'
TO ('/oracle/dbs/log2a.rdo', '/oracle/dbs/log2b.rdo');Il faut spécifier le nom du nouveau membre en entier en indiquant son chemin dans l'OS. Sinon, le fichier sera créé dans le répertoire par défaut ou dans le répertoire courant suivant l'OS. Il faut noter aussi que le statut du nouveau membre est INVALID. C'est normal, il prendra la valeur vide dès sa première utilisation.
IV. Remplacement et renomination des membres de fichiers redo▲
On peut utiliser les commandes OS pour déplacer les fichiers redo. Après on utilise la commande ALTER DATABSE pour donner leurs nouveaux noms (emplacement) connus par la base. Cette procédure est nécessaire, par exemple, si le disque, actuellement utilisé pour certains fichiers redo, doit être retiré, ou si les fichiers de données et certains fichiers redo se trouvent dans un même disque et devraient être séparés pour réduire la contention.
Pour renommer un membre de fichiers redo, on doit avoir le privilège système ALTER DATABASE.
En plus, on doit aussi avoir les privilèges système pour copier les fichiers dans le répertoire désiré et les privilèges pour ouvrir et sauvegarder la base de données.
Avant de déplacer les fichiers redo, ou tous autres changements de structures de la base, sauvegarder complètement la base. Par précaution, après la renomination ou le déplacement d'un ensemble de fichiers redo, effectuer immédiatement une sauvegarde du fichier de contrôle.
Pour déplacer les fichiers redo, on utilise les méthodes suivantes :
- les fichiers redo sont situés dans deux disques : diska et diskb ;
- les fichiers redo sont dupliqués : un groupe est constitué des membres /diska/logs/log1a.rdo et /diskb/logs/log1b.rdo, et le second groupe est constitué des membres /diska/logs/log2a.rdo et /diskb/logs/log2b.rdo ;
- les fichiers redo situés dans le disque diska doivent être déplacés dans le diskc. le nouveau nom du fichier reflète le nouvel emplacement : /diskc/logs/log1c.rdo et /diskc/logs/log2c.rdo.
Les étapes à suivre pour renommer les membres des fichiers redo :
1. Arrêter la base.
SHUTDOWN IMMEDIAT2. Copier les fichiers redo dans le nouvel emplacement.
On peut utiliser la commande HOST pour lancer des commandes OS sans sortir de SQL*Plus. Sous certains OS on utilise un caractère à la place de HOST. Par exemple, sous UNIX on utilise le point d'exclamation (!).
L'exemple suivant utilise les commandes OS (UNIX) pour déplacer les membres des fichiers redo dans un nouvel emplacement :
mv /diska/logs/log1a.rdo /diskc/logs/log1c.rdo
mv /diska/logs/log2a.rdo /diskc/logs/log2c.rdo3. Démarrer la base avec un mount, sans l'ouvrir.
CONNECT / as SYSDBA
STARTUP MOUNT4. Renommer le membre du fichier redo.
ALTER DATABASE
RENAME FILE '/diska/logs/log1a.rdo', '/diska/logs/log2a.rdo'
TO '/diskc/logs/log1c.rdo', '/diskc/logs/log2c.rdo';5. Ouvrir la base normalement.
La modification du fichier redo prend effet à l'ouverture de la base.
ALTER DATABASE OPEN;V. Suppression du groupe de fichiers redo▲
Dans certains cas, on doit supprimer un groupe en entier. Par exemple, on veut réduire le nombre de groupes. Dans d'autres cas, on doit supprimer un ou plusieurs membres. Par exemple, si certains membres se trouvent dans un disque défaillant.

Pour supprimer un groupe de fichiers redo, on doit avoir le privilège système ALTER DATABASE.
Avant de supprimer un groupe de fichiers redo, il faut prendre en considération les restrictions et les précautions suivantes :
- une instance réclame au minimum deux groupes de fichiers redo, sans se soucier du nombre de membres dans le groupe. (Un groupe contient un ou plusieurs membres.) ;
- on peut supprimer un groupe de fichiers redo, seulement s'il est inactif. Si on a besoin de supprimer le groupe courant, en premier, on force un switch log ;
- s'assurer que le groupe de fichiers redo est bien archivé (si l'archivage est activé) avant de le supprimer.
Pour voir ce qui se passe, utilisez la vue V$LOG.
SQL> SELECT GROUP#, ARCHIVED, STATUS FROM V$LOG;
GROUP# ARC STATUS
---------- --- ----------------
1 YES ACTIVE
2 NO CURRENT
3 YES INACTIVE
4 YES INACTIVESupprimer un groupe de fichiers redo avec la commande ALTER DATABASE en utilisant la clause DROP LOGFILE.
Dans cet exemple on supprime le groupe numéro 3 :
ALTER DATABASE DROP LOGFILE GROUP 3;Quand un groupe est supprimé de la base et que l'on n'utilise pas l'OMF, les fichiers OS ne seront pas supprimés du disque. Il faut utiliser les commandes OS pour les supprimer physiquement.
Quand on utilise OMF, le nettoyage des fichiers OS se fait automatiquement.
VI. Suppression des membres de fichiers redo▲
Pour supprimer un membre d'un fichier redo, on doit avoir le privilège système ALTER DATABASE.
Pour supprimer un membre inactive d'un fichier redo, on utilise la commande ALTER DATABASE avec la clause DROP LOGFILE MEMBER.

La commande suivante supprime le journal /oracle/dbs/log3c.rdo :
ALTER DATABASE DROP LOGFILE MEMBER '/oracle/dbs/log3c.rdo';Quand un membre d'un journal est supprimé, le fichier OS n'est pas supprimé du disque.
Pour supprimer un membre d'un groupe actif, on doit forcer en premier le log switch.
VII. Forcer les Logs Switchs▲
Le log switch se produit quand LGWR s'arrête d'écrire dans un groupe de journaux et commence à écrire dans un autre. Par défaut, un log switch se produit automatiquement quand le groupe du fichier redo en cours est rempli.
On peut forcer un log switch pour que le groupe courant soit inactif et disponible pour des opérations de maintenance sur les fichiers redo. Par exemple, on veut supprimer le groupe actuellement actif, mais on est incapable de le supprimer tant qu'il est actif. On doit aussi obliger un switch log si le groupe actuellement actif a besoin d'être archivé à un moment spécifique avant que les membres du groupe soient complètement remplis. Cette option est utile dans des configurations où les fichiers redo sont assez larges et prennent plus de temps pour se remplir.
Pour forcer un log switch, on doit avoir le privilège ALTER SYSTEM. Utilisez la commande ALTER SYSTEM avec la clause SWITCH LOGFILE.
La commande suivante force un log switch:
ALTER SYSTEM SWITCH LOGFILE;|
Avant le log switch |
Après le log switch |
|
|
|


Oracle conseille un switch de fichier redo toutes les 30 minutes.
VIII. Vérification des blocs dans les fichiers redo▲
On peut configurer la base pour utiliser le CHECKSUM, afin que les blocs des fichiers redo soient vérifiés. Si l'on affecte le paramètre d'initialisation DB_BLOCK_CHECKSUM à TRUE, Oracle calcule le checksum pour chaque bloc oracle quand il écrit dans le disque, y compris les blocs des journaux. Le checksum est stocké dans l'en-tête du bloc.
Oracle utilise le checksum pour détecter les blocs corrompus dans les fichiers redo. La base vérifie le bloc du journal quand le bloc est lu à partir du journal archivé durant la restauration et quand il écrit le bloc dans le journal archivé. Une erreur sera détectée et écrite dans le fichier d'alerte si une corruption est détectée.
Si une corruption est détectée dans un bloc du journal pendant son archivage, le système tente de lire le bloc depuis un autre membre dans le groupe. Si le bloc est corrompu dans tous les membres du groupe des journaux, alors l'archivage ne peut pas se poursuivre.
La valeur par défaut du paramètre DB_BLOCK_CHECKSUM est TRUE. La valeur de ce paramètre peut être modifiée dynamiquement en utilisant ALTER SYSTEM.
L'activation de DB_BLOCK_CHECKSUM diminue la performance de la base. Il faut bien surveiller les performances de la base pour décider s'il est avantageux d'utiliser le checksum de bloc de données.
IX. Initialisation des fichiers redo▲
On peut initialiser un fichier redo sans arrêter la base, par exemple, si le fichier redo est corrompu.

ALTER DATABASE CLEAR LOGFILE GROUP (numero du groupe);On peut utiliser cette commande si on ne peut pas supprimer les fichiers redo , il y a deux situations :
- s'il y a seulement deux groupes de journaux ;
- le journal corrompu appartient au groupe en cours.
Si le fichier redo corrompu n'est pas encore archivé, on utilise la clé UNARCHIVED.
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP (numero du groupe);Cette commande initialise les fichiers redo corrompus et évite leur archivage.
Si l'on initialise le fichier redo nécessaire à la restauration ou à la sauvegarde, on ne peut plus restaurer depuis cette sauvegarde.
Si on initialise un fichier redo non archivé, on devrait faire une autre sauvegarde de la base.
Pour initialiser un fichier redo non archivé qui est nécessaire pour mettre un tablespace hors ligne en ligne, on utilise la clause UNRECOVERABLE DATAFILE dans la commande DATABASE CLEAR LOGFILE.
Si on initialise un fichier redo nécessaire pour mettre un tablespace hors ligne en ligne, on sera incapable de mettre le tablespace en ligne une autre fois. On est obligé de supprimer le tablespace ou effectuer une restauration incomplète. Il faut noter que le tablespace mis hors ligne normalement n'a pas besoin de restauration.
X. Test sur les fichiers redo▲
|
T1 |
Dans une seule instance Oracle, on peut avoir : |
|---|---|
|
|
Un seul thread |
|
|
Deux threads |
|
|
Quatre threads |
|
|
Aucun thread |
|
T2 |
Les fichiers redo sont remplis par des enregistrements |
|---|---|
|
|
Undo |
|
|
Redo |
|
|
Vecteurs de journaux |
|
|
Vecteurs de changements |
|
T3 |
Les enregistrements redo sont écrits dans le fichier redo par le processus |
|---|---|
|
|
DBWR |
|
|
CKPT |
|
|
LGWR |
|
|
RDWR |
|
T4 |
Les enregistrements redo peuvent aussi être écrits dans le fichier redo avant que |
|---|---|
|
|
le buffer redo log soit plein |
|
|
Le processus LGWR lui a attribué un numéro SCN |
|
|
la transaction correspondante soit validée. |
|
T5 |
La base oracle exige au minimum |
|---|---|
|
|
trois fichiers de journalisation. |
|
|
aucun fichier de journalisation. |
|
|
un fichier de journalisation. |
|
|
deux fichiers de journalisation. |
|
T6 |
LGWR commence à écrire dans le prochain fichier journal redo disponible |
|---|---|
|
|
Quand tous les fichiers redo sont pleins |
|
|
Quand le fichier redo courant est plein |
|
|
Quand on fait un switch log |
|
|
Quand on arrête la base par un SHUTDOWN IMMEDIATE |
|
T7 |
Dans une base en mode ARCHIVELOG, un fichier de journalisation plein est disponible pour le processus LGWR après que |
|---|---|
|
|
Son contenu soit écrit dans les fichiers de données |
|
|
Son contenu soit vidé |
|
|
Sans condition |
|
|
Son contenu soit écrit dans les fichiers de données et il est bien archivé |
|
T8 |
Un log switch survient |
|---|---|
|
|
quand le fichier de journalisation courant est complètement rempli |
|
|
quand le fichier de journalisation courant est 1/3 rempli |
|
|
après la commande ALTER SYSTEM SWITCH LOGFILE; |
|
|
après la commande ALTER SYSTEM SWITCH LOG FILE; |
|
T9 |
Chaque fichier de journalisation ou archive est identifié uniquement par |
|---|---|
|
|
un RBA |
|
|
un SCN |
|
|
son numéro de séquence |
|
|
son RDBA |
|
T10 |
Les vues suivantes donnent des informations sur le fichier de journalisation |
|---|---|
|
|
V$LOGFILE |
|
|
V$LOGFILES |
|
|
V$THREADS |
|
|
V$THREAD |
|
T11 |
La seule solution pour initialiser la vue V$LOG_HISTORY |
|---|---|
|
|
modifier le paramètre CONTROL_FILE_RECORD_KEEP_TIME |
|
|
en ajoutant un nouveau groupe de fichiers redo |
|
|
en ajoutant un nouveau membre de fichiers redo |
|
|
recréer le fichier de contrôle |
|
T12 |
Le numéro de groupe doit être entre |
|---|---|
|
|
1 et MAXLOGMEMBER |
|
|
1 et 10 |
|
|
1 et MAXLOGFILES |
|
|
1 et MAXLOGMEMBERS |
|
T13 |
Pour supprimer un groupe de journaux, on doit avoir le privilège système |
|---|---|
|
|
ALTER LOGFILE |
|
|
ALTER SYSTEM |
|
|
ALTER DATABASE |
|
|
Aucun privilège système |
|
T14 |
On peut supprimer un groupe de journaux, seulement s'il est |
|---|---|
|
|
INACTIF |
|
|
OFFLINE |
|
|
ACTIF |
|
|
sans se soucier s'il est INACTIF, OFFLINE ou ACTIF |
|
T15 |
Pour supprimer le groupe 3 physiquement (sans OMF) : |
|---|---|
|
|
Avec la commande ALTER DATABASE DROP LOGFILE OS GROUP 3 |
|
|
les fichiers OS ne seront pas supprimés du disque |
|
|
les fichiers OS seront supprimés du disque |
|
|
Il faut utiliser les commandes OS pour les supprimer physiquement |
|
T16 |
La commande suivante supprime le journal /oracle/dbs/log3c.rdo |
|---|---|
|
|
ALTER DATABASE DROP MEMBER '/oracle/dbs/log3c.rdo'; |
|
|
ALTER DATABASE DROP LOGFILE '/oracle/dbs/log3c.rdo'; |
|
|
ALTER DATABASE DROP LOGFILE MEMBER '/oracle/dbs/log3c.rdo'; |
|
|
ALTER SYSTEM DROP LOGFILE MEMBER '/oracle/dbs/log3c.rdo'; |
|
T17 |
La commande suivante force un log switch |
|---|---|
|
|
ALTER SYSTEM SWITCH LOGFILE; |
|
|
ALTER DATABASE SWITCH LOGFILE; |
|
|
ALTER SYSTEM SWITCH LOG FILES; |
|
|
ALTER DATABASE SWITCH LOG FILES; |
|
T18 |
Dans 10g la valeur du paramètre DB_BLOCK_CHECKSUM |
|---|---|
|
|
la valeur à TRUE augmente la performance de la base |
|
|
la valeur à TRUE diminue la performance de la base |
|
|
par défaut est FALSE |
|
|
par défaut est TRUE |
|
T19 |
On peut initialiser un fichier de journalisation sans arrêter la base avec la commande |
|---|---|
|
|
ALTER DATABASE CLEAR GROUP (numero du groupe); |
|
|
ALTER DATABASE INITIALIZE GROUP (numero du groupe); |
|
|
ALTER DATABASE INITIALIZE LOGFILE GROUP (numero du groupe); |
|
|
ALTER DATABASE CLEAR LOGFILE GROUP (numero du groupe); |
|
T20 |
Pour initialiser un journal non archivé qui est nécessaire pour mettre un tablespace hors ligne en ligne, on utilise |
|---|---|
|
|
la clause UNARCHIVED DATAFILE dans la commande DATABASE CLEAR LOGFILE |
|
|
la clause UNRECOVERABLE DATAFILE dans la commande DATABASE CLEAR LOGFILE |
|
|
la clause UNARCHIVED LOGFFILE dans la commande DATABASE CLEAR LOGFILE |
|
|
la clause UNRECOVERABLE LOGFILE dans la commande DATABASE CLEAR LOGFILE |
Solutions :
T1 : A
T2 : B et D
T3 : C
T4 : A et C
T5 : D
T6 : B et C
T7 : D
T8 : A et C
T9 : A
T10 : A et D
T11 : A et D
T12 : C
T13 : C
T14 : A
T15 : B et D
T16 : C
T17 : A
T18 : B et D
T19 : D
T20 : B