Dump des fichiers RedoDate de publication : le 26 Septembre 2006
Cet article vous montre les multiples possibilités qu'offrait Oracle
d'exporter les informations des fichiers REDO
I. Introduction II. Notions Internes A. Le vecteur de changement B. L'enregistrement redo C. RBA D. DBA E. Opcode 1. Opérations sur les Lignes (Row Operations) 2. Opérations sur les transactions 3. Opérations sur les Indexes 4. Block Cleanout 5. Opérations du Hot Backup 6. Opérations sur les écritures de blocs 7. Opérations sur le Direct Loads III. Décharge du fichier de journalisation A. Dump basé sur le DBA (Data Block Address) B. Dump basé sur le RBA (Redo Block Address) C. Dump basé sur le temps D. Dump basé sur le SCN E. Dump basé sur la couche et l'opcode F. Dump du fichier de journalisation en entier G. Décharge de l'entête des fichiers de journalisations IV. Contenu d'un fichier de journalisation A. L'entête d'un fichier de journalisation V. Exemples A. Exemples sur un cas de corruption B. Exemples sur cas de perte de données
I. Introduction
Les fichiers de journalisation gardent des informations sur les undo et les redo à chaque
modification atomique de la base. Ces informations sont enregistrées comme des opcodes, qui
sont normalement de la forme code.operation . Par exemple, l'opcode 4.1 désigne l'opération
de nettoyage du bloc dans la couche transaction du bloc.
La décharge d'un fichier de journalisation est normalement demandé par le support oracle pour analyser
les corruptions de données (corruption logique). Il peut être utiliser comme un utilitaire d'audit.
Par exemple, si on veut connaître l'heure et la date des extents alloués pour un segment,
on peut décharger l'opcode approprié de l'allocation d'extent à partir d'un ensemble de redo ou
de fichiers d'archives et obtenir des détails qu'on ne le trouve nulle part dans le dictionnaire
de données.
II. Notions InternesA. Le vecteur de changement
Le vecteur de changement décrit un changement d'un simple bloc de données. Il peut être appliqué sur
Il est crée dans le PGA avant que le tampon du bloc de données soit modifié.
Il est constitué de :
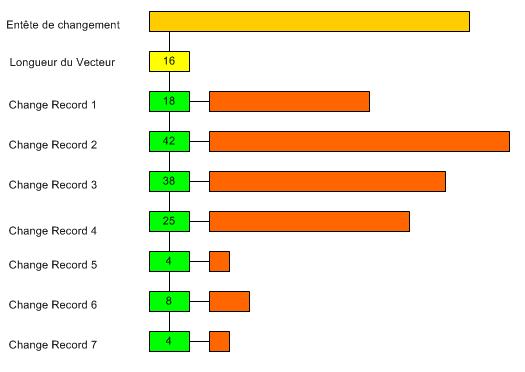
Chaque vecteur de changement à un entête et voici un exemple :
Dans l'entête on a :
La classe dans l'entête d'enregistrement est equivalente à CLASS dans la table système X$BH.
B. L'enregistrement redo
Un enregistrement redo est constitué :
Chaque enregistrement redo contient un undo et un redo pour une modification atomique,
et certains changements n'ont pas besoin d'un undo.

Exemple de l'entête d'un enregistrement redo :
L'entête contient :
C. RBA
L'emplacement de chaque entrée redo est identifié par un RBA qui est constitués de trois parties :
pour le RBA: 0x000047.000018b8.003c

La notion du RBA est utilisée dans différentes façons, par exemple :
low RBA, High RBA, checkpoint RBA, on-disk RBA, sync RBA.
D. DBA
Chaque bloc de la base est identifié uniquement par un DBA (Adresse du Bloc de Données,
il ne faut pas confondre avec l'administrateur de bases de données) qui est constitué du
numéro du fichier de données et du numéro du bloc dans le fichier de données.
Pour calculer le DBA d'un bloc qui se trouve dans un fichier de donnée, on utilise la fonction
make_data_block_address du paquetage dbms_utility.
Par exemple pour calculer le dba du bloc 7 dans le fichier de donnée 5
Après, Il faut convertir la valeur trouvée en Hexadécimal
Donc le DBA du bloc 7 dans le fichier de donnée 5 est 1400007
Supposons qu'on connaît le DBA et on veut trouver le numéro du bloc et le numéro du fichier de données.
Prenons comme DBA la valeur 1400007
Sa valeur en décimal
Le numéro du bloc
Le numéro du fichier de données
Donc, pour décharger tous les enregistrements redo dans un rangée de
blocs de données specifié par file# et bloc#..
A partir de SQL, en lance la commande suivante :
Exemple:
E. Opcode
Chaque changement est representé par une opération dans le fichier de journalisation,
et chaque opération est representée par une couche et un code de l'opération.
On cite ici certains couches :
1. Opérations sur les Lignes (Row Operations)
Les opération sur les lignes sont generés par la couche 11, on a :
A. Insertion d'une simple ligne 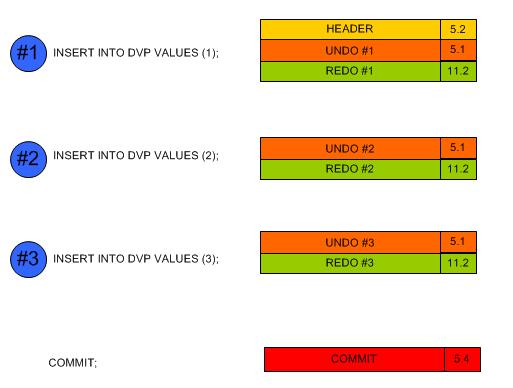
B. Insertion multi-lignes
D. Mise à jours d'une seule ligne
Quand un utilisateur fait une mise à jours d'une ligne sur une table, Oracle insère une entrée
dans l'entête du bloc de données en indiquent quelle partie du bloc à été modifié et quel
segment rollback tient l'information undo. Si un autre utilisateur exécute une requête
qui lit ce même bloc avant que le premier utilisateur à valider sa modification, la requête
du deuxième utilisateur regarde dans le segment rollback qui lui fournit les données avant la validation.
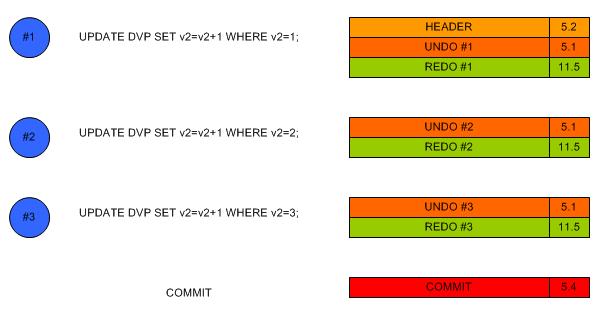
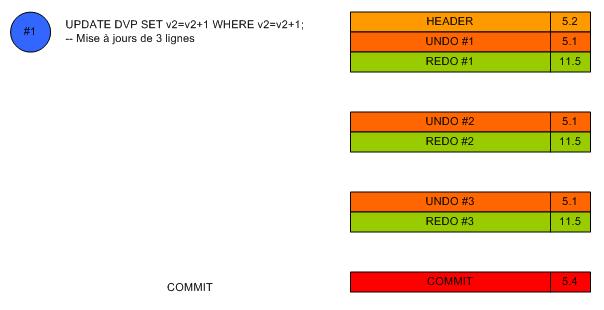
E. Mise à jours multi-lignes
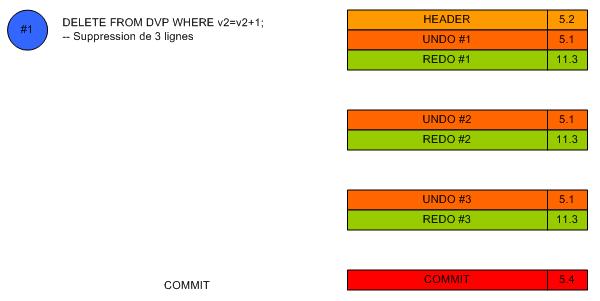
F. Suppression d'une seule ligne
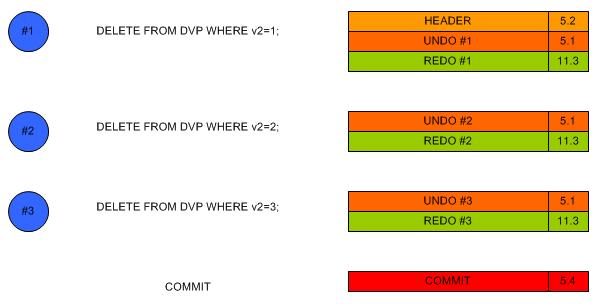
G. Suppression multi-lignes
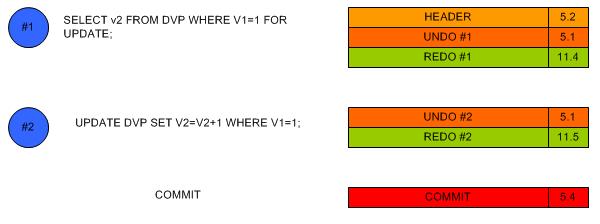
H. Select for update pour une seule ligne
L'expression SELECT FOR UPDATE dans une requêtte génère des entrées redo car Oracle doit créer des verrous
pour réserver les lignes demandés pour une mise à jours.
I. Select for update pour plusieurs lignes

J. ROLLBACK
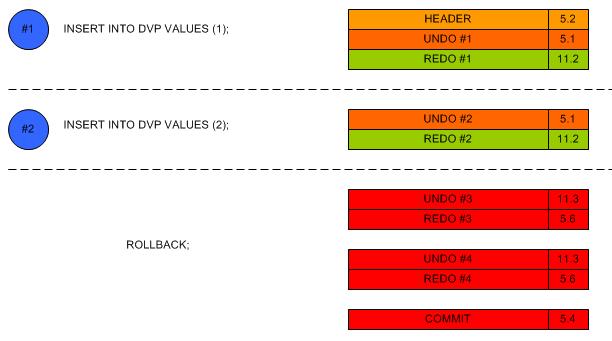 2. Opérations sur les transactions3. Opérations sur les Indexes
Les opérations sur les indexes sont génèrés par la caouche 10.
A. Insertion dans une table indexé 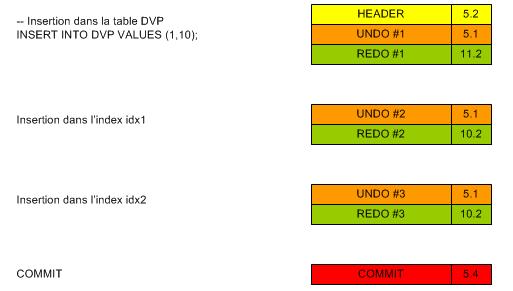
B. Mise à jours dans une table indexé 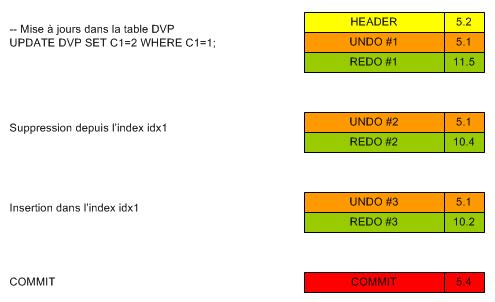
A. Suppression dans une table indexé 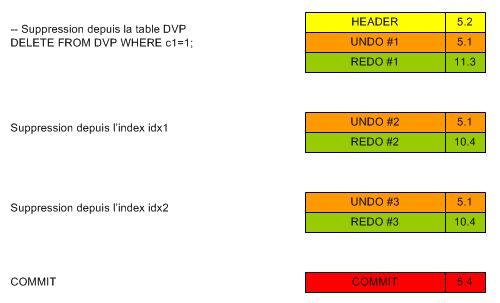
4. Block Cleanout
Quand l'utilisateur valide une transaction, Oracle mis à jours l'entête du segment rollback.
Oracle essaye aussi de trouver les blocs de données c.a.d modifié par la transaction et mis à jours
l'entête dans les blocs pour indiquer que la modification à été bien validé. Ce qu'on appelle
une validation cleanout. Oracle garde une courte liste de blocs de données affectées par chaque
transaction pour connaître quels blocs ont besoins d'un cleanout au moment de la validation.
Si une transaction met à jours trop de blocs pour qu'oracle les gardent dans sa liste courte ou
si le bloc modifé n'est plus dans le buffer cache au moment de la validation ou si le bloc est dans
le buffer cache mais verrouillé par une autre session, alors oracle ne doit pas nettoyer tous les blocs
affectés au moment de la validation. On appelle cela commit cleanout failures.
Si oracle échoue de nettoyer l'entête du bloc au moment de la validation, alors ce bloc de donnée doit
incorrectement indiquer que cette portion de bloc à été mis à jours par une transaction non validé.
La prochaine fois qu'oracle lit ce bloc de donnée, il devrait détecter une incohérence dans l'entête
du bloc et le corrige. C'est le delayed block cleanout. Si Oracle découvre une telle condition en
traitant une requête, par exemple, alors il interrompe le traitement de la requête pour effectuer
le delayed block cleanout. Cela génère des entrées redo et ralenti l'exécution de la requête.
Cela explique qu'une simple opération de lecture , par exemple SELECT, peut générer des entrées redo.
On crée la table DVP3.
On active la trace des statistqiues.
On insère 500 lignes dans la table DVP3.
Dans la première requête la taille des redo génèrés est de 536.
Dans la deuxième requête la taille des redo génèrés est 0.
5. Opérations du Hot Backup
Pendant la sauvegarde à chaud, des informations supplementaires sont enregistrés dans le fichier
de journalisation en ligne.
La première fois qu'un bloc à été modifié dans un fichier de données en mode hot backup, le bloc
en entier est écrits dans le fichier de journalisation, et non seulement les octets modifiés c.a.d les redo
vector. Car, on peut se trouver dans la situation où le processus de sauvegarde est entrain de copier
le fichier de données et en même temps DBWR écrit simultanement dans le même bloc. L'opcode est 18.1
A chaque fichier de données d'un tablespace, correspond un enregistrement redo contenant son numéro de
fichier de données et son SCN de BEGIN BACKUP. Dans mon exemple, j'ai deux enregistrements redo
pour le BEGIN BACKUP.
et
Le premier, concerne ma table DVP ayant pour numéro d'objet : 53556 et le deuxième, concerne l'index de DVP
ayant pour numéro d'objet : 533557. On peut utiliser la vue ALL_OBJECTS :
et
Quand le mode de sauvegade est désactivé, un marqueur fin de sauvegarde est écrit dans le fichier
de journalisation (17.1).
6. Opérations sur les écritures de blocs
Depuis Oracle 9.0.1 les blocs écrits depuis le buffer cache vers le disque par
le processus DBWR sont écrites dans les fichiers de journalisations.
7. Opérations sur le Direct Loads
Si le mode d'archivage est activé, les blocs du direct load sont écrites dans les fichiers de journalisation.
Dans Oracle 9.2, chaque bloc exige les changements 19.1 et 24.2
Ici, on voit bien que le LOB passe bien par un chargement direct.
III. Décharge du fichier de journalisationA. Dump basé sur le DBA (Data Block Address)Donc, pour décharger tous les enregistrements redo dans un rangée de
blocs de données specifié par file# et bloc#..
A partir de SQL, en lance la commande suivante :
Exemple:
B. Dump basé sur le RBA (Redo Block Address)
Ici, on décharge tous les enregistrements redo entre deux adresses redo spécifiés par
un numéro de séquence et un numéro de bloc.
Example:
C. Dump basé sur le temps
Cette option devrait provoquer la décharge des enregistrements redo crées entre deux dates.
Pour décharger le fichier redo suivant les dates, on utilise la commande suivante :
Par exemple:
time = (((((yyyy - 1988)) * 12 + mm - 1) * 31 + dd - 1) * 24 + hh) * 60 + mi) * 60 + ss;
D. Dump basé sur le SCN
Cette option, consiste à décharger les enregistrements redo possédant
un SCN rangée entre minscn et maxscn.
E. Dump basé sur la couche et l'opcode
LAYER et OPCODE sont utilisés pour décharger tous les enregistrements d'un type particulier.
Depuis la commande SQL :
Par exemple:
F. Dump du fichier de journalisation en entier
A partir de SQL on peut lancer la commande suivante :
Par exemple:
G. Décharge de l'entête des fichiers de journalisations
Cette commande décharge les informations des entêtes de tous les fichiers redo en ligne.
A partir de SQL :
La commande décharge les entêtes de tous les fichiers journaux
IV. Contenu d'un fichier de journalisationA. L'entête d'un fichier de journalisation
V. ExemplesA. Exemples sur un cas de corruptionB. Exemples sur cas de perte de données
Supposons qu'un utilisateur à supprimer une table qui n'a pas été sauvegardé la nuit précédente. Pris de panique pendant un certain temps avant d'appeler le DBA.
La solution, est d'arrêter la base proprement, de restaurer la base juste avant la suppression de la table, de faire l'export de la table, de continuer la restauration jusqu'à que tous les redologs sont appliqués et enfin importer la table.
Ainsi, on a besoin de connaître exactement le SCN qui a provoqué la suppression de la table.
On décharge le fichier redolog, en limitant le fichier dump dans la période qui nous intéresses. Avec un éditeur, on visualise le fichier dump et on cherche l'opération DDL qui a supprimé la table.
Quand on exécute une opération DDL, Oracle effectue des opérations DML sur les tables de dictionnaires de données : FET$, UET$ et OBJ$. La table OBJ$ nous intéresse, car il contient le nom de l'objet, et dans notre cas c'est la table SALES_DATA.
On peut trouver OBJ# de la table OBJ$ en utilisant la requête suivante :
Si on effectue un describe de la table OBJ#, le nom de l'objet se trouvera dans la quatrième colonne avec un type VARCHAR2. Donc, on est entrains de chercher les opérations sur l'objet 3202 ou la colonne 4 contient le string 'SALES_DATA', en hexadécimal est : 53 41 4c 45 53 5f 44 41 54 41.
Ce document est issu de http://www.developpez.com et reste la propriété exclusive de son auteur.
La copie, modification et/ou distribution par quelque moyen que ce soit est soumise à l'obtention préalable de l'autorisation de l'auteur.
|


